コアノード
ComfyUIの画像操作、コンディショニングなどのコアノードについて学び、強力なAIアートワークフローを構築しましょう。
Image
Pad Image for Outpainting
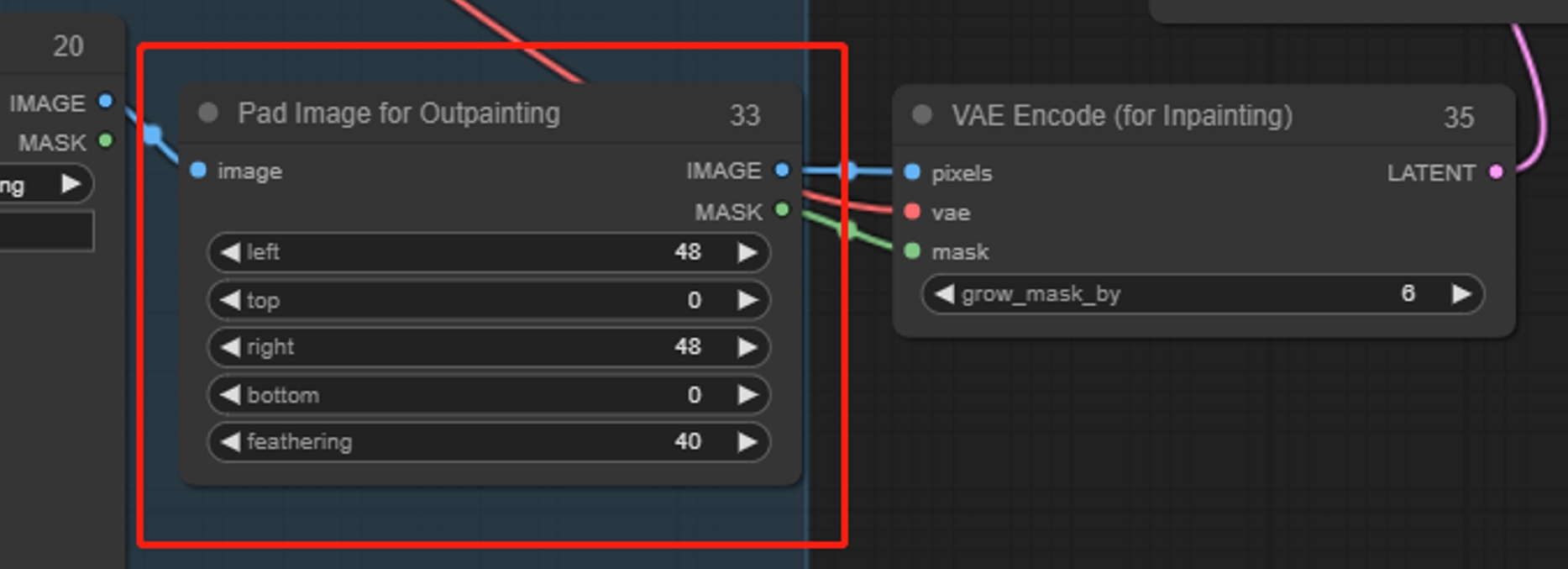
画像を埋め込み、拡張することは、拡大と似ています。まず画像のサイズを増やし、次に拡張された領域をマスクとして描きます。元の画像が変更されないようにするために、VAEエンコード(インペイント用)を使用することをお勧めします。
パラメータ:
left、top、right、bottom: 上下左右のパディング量
feathering: エッジのフェザリングの度合い
Save Image
Load Image
ImageBlur
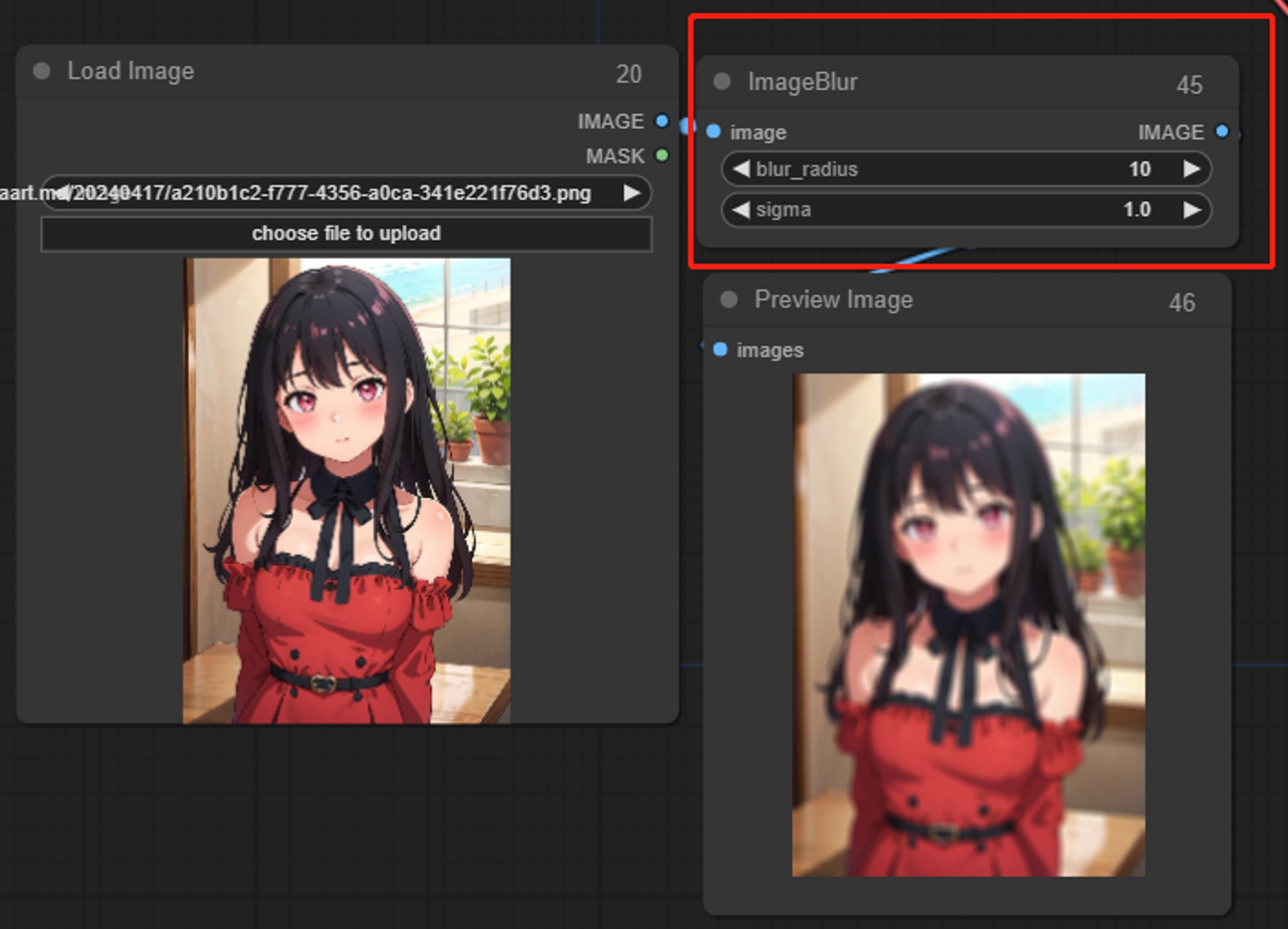
画像にぼかし効果を追加
パラメータ:
sigma: 値が小さいほど、中央ピクセル周辺のぼかしが集中します。
Image Blend
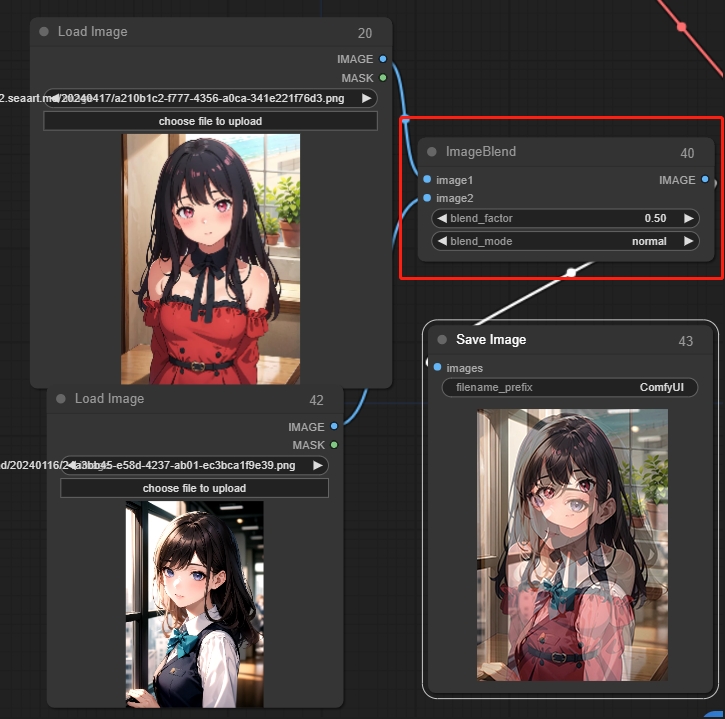
2つの画像を透明度を使ってブレンドすることができます。
Image Quantize
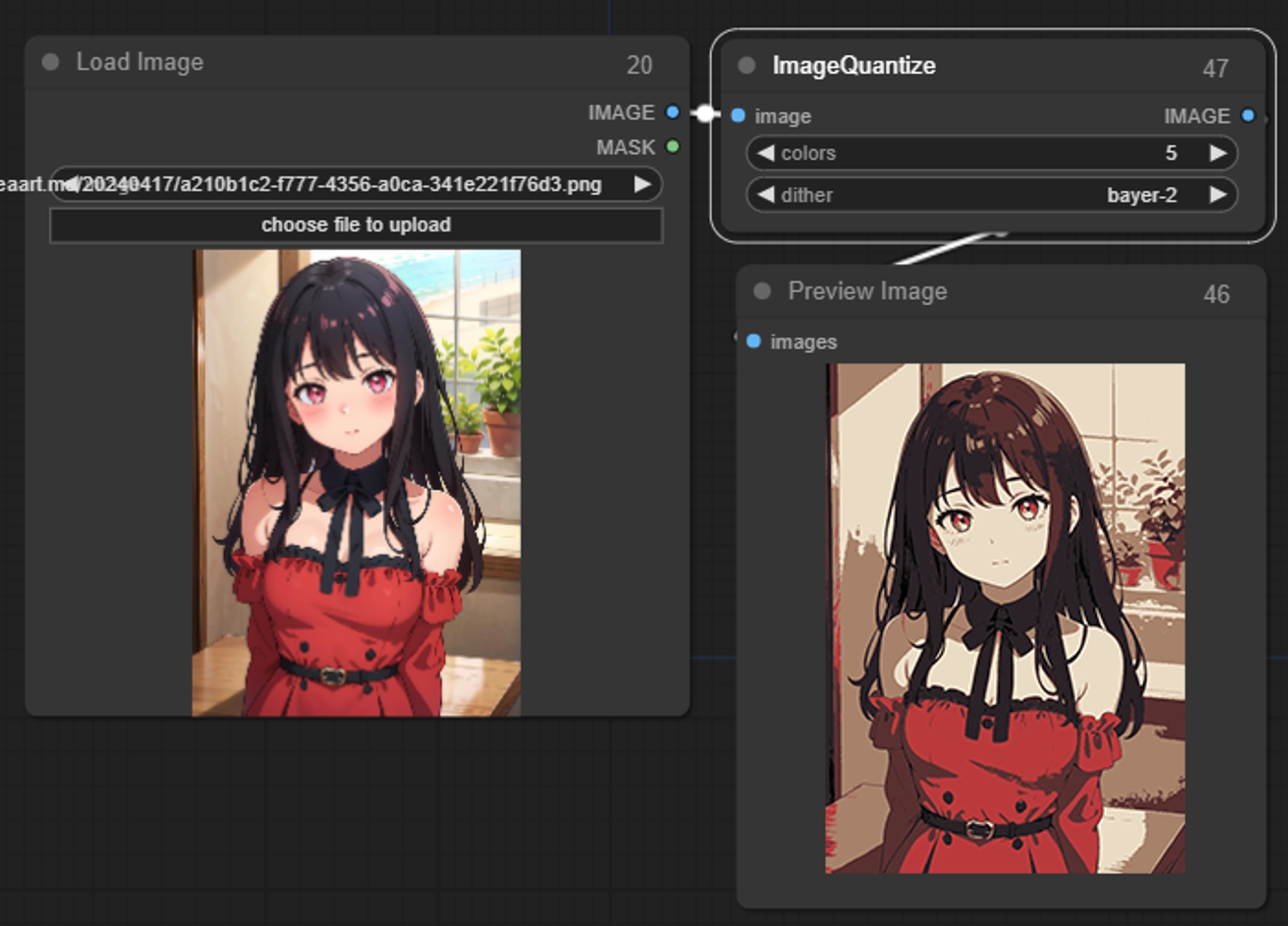
画像の色数を減らす
パラメータ:
colors: 画像の色数を量子化します。1に設定すると、画像は1色だけになります。
dither: 量子化された画像を滑らかに見せるためにディザリングを使用するかどうか。
Image Sharpen
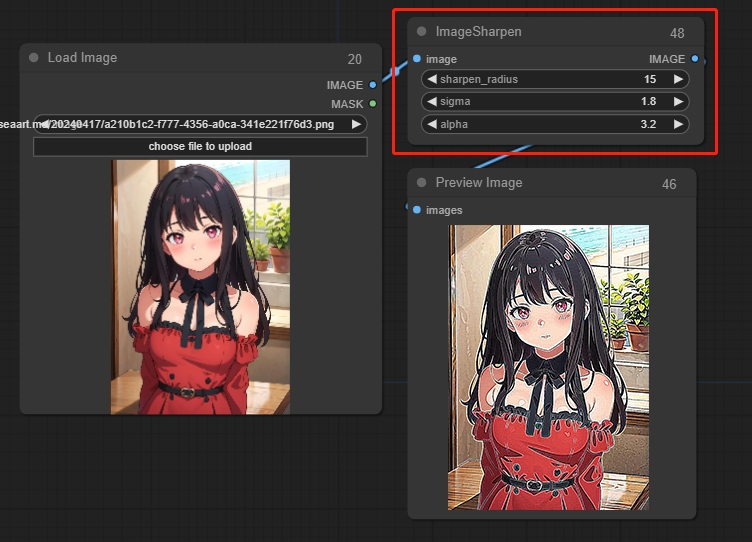
パラメータ:
sigma: 値が小さいほど、中央ピクセル周辺のシャープ化が集中します。
Invert Image
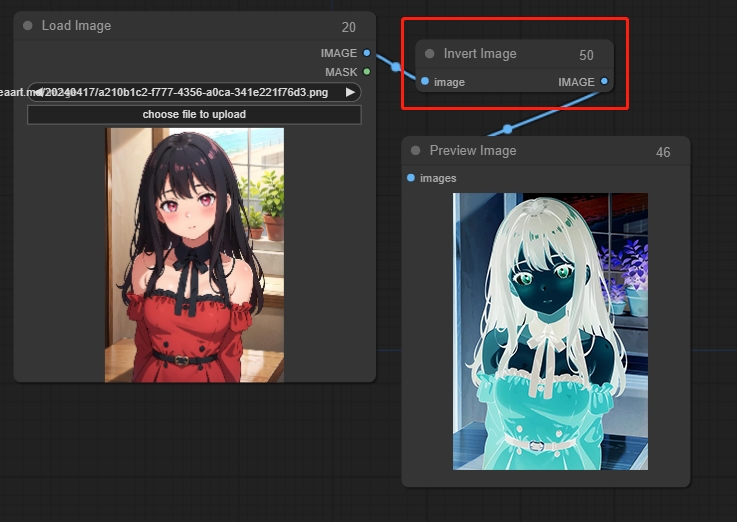
画像の色を反転する
Upscaling
9.1 Upscale Image (Using Model)
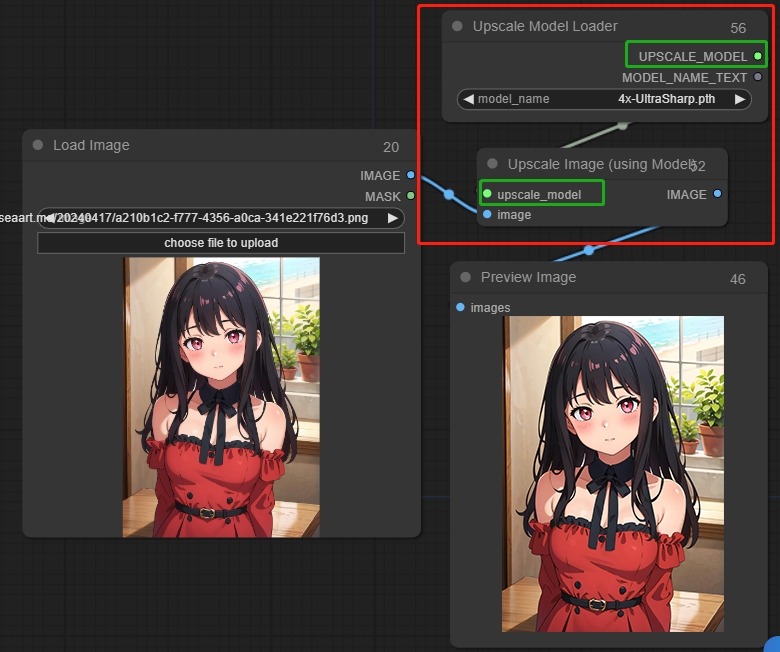
9.2 Upscale Image
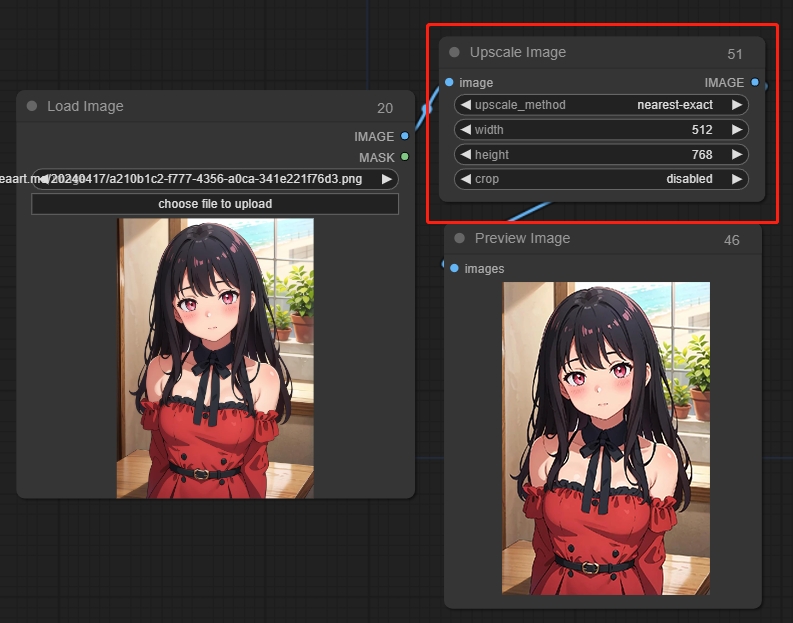
アップスケール画像ノードはピクセル画像のサイズ変更に使用できます。
パラメータ:
upscale_method: ピクセル埋めの方法を選択します。
width: 調整された画像の幅
height: 調整された画像の高さ
crop: 画像をクロップするかどうか
Preview Image
Loaders
Load CLIP Vision
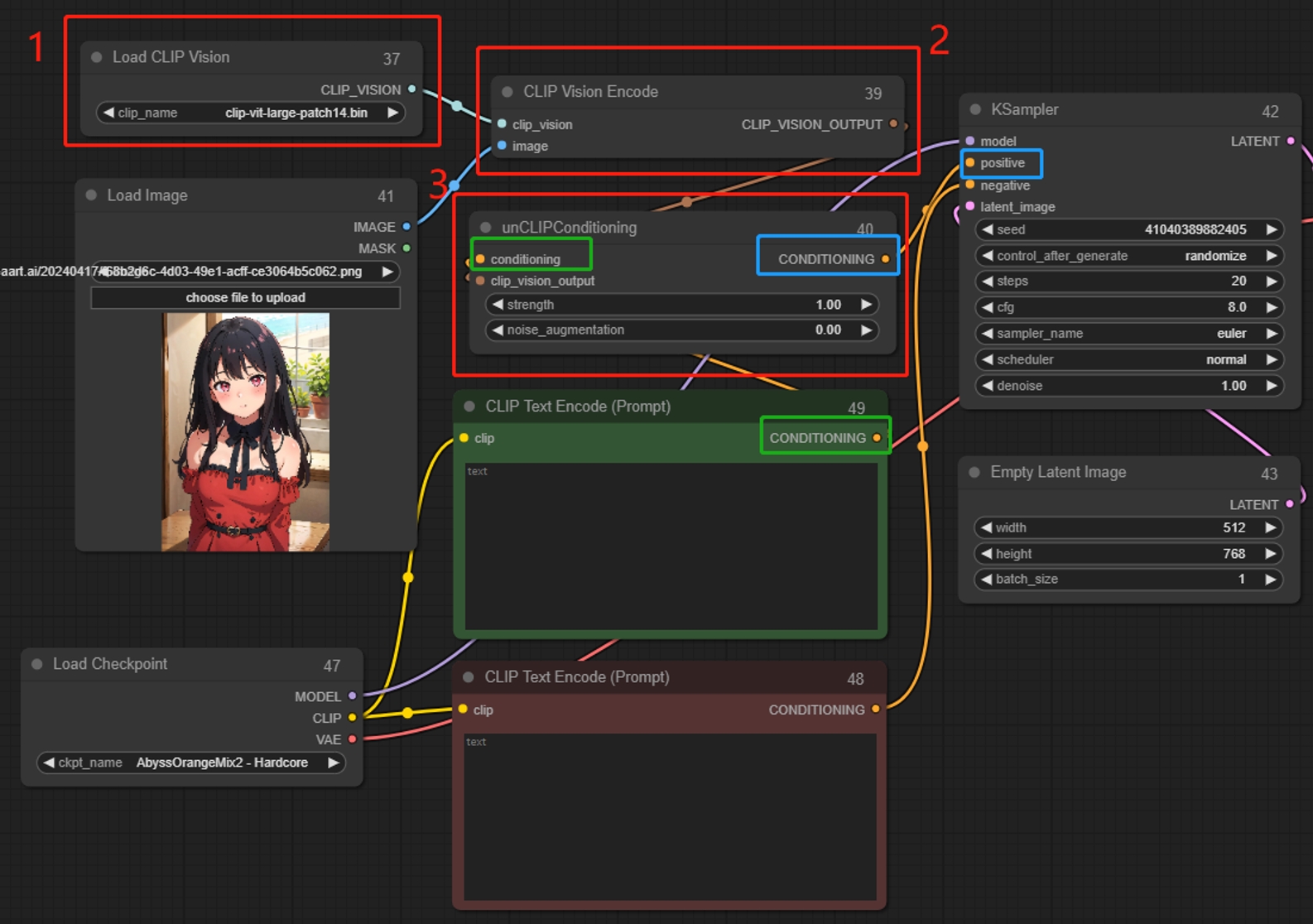
画像をデコードして説明(プロンプト)を生成し、それらをサンプラーの条件付き入力に変換します。デコードされた説明(プロンプト)に基づいて、新しい類似画像を生成します。複数のノードを一緒に使用できます。概念や抽象的なものを変換するのに適しており、Clip Vision Encodeと組み合わせて使用します。
Load CLIP
Load CLIPノードは特定のCLIPモデルをロードするために使用できます。CLIPモデルは、拡散プロセスをガイドするテキストプロンプトをエンコードするために使用されます。
*条件付き拡散モデルは特定のCLIPモデルを使用してトレーニングされているため、異なるモデルを使用すると良好な画像が得られない可能性があります。Load Checkpointノードは正しいCLIPモデルを自動的にロードします。.
unCLIP Checkpoint Loader
unCLIP Checkpoint Loaderノードは、unCLIPと連携するために特別に作られた拡散モデルをロードするために使用できます。unCLIP拡散モデルは、提供されたテキストプロンプトだけでなく、提供された画像にも条件付けられた潜在画像のノイズを除去するために使用されます。このノードは、適切なVAEおよびCLIPビジョンモデルも提供します。
*このノードはすべての拡散モデルをロードするために使用できますが、すべての拡散モデルがunCLIPと互換性があるわけではありません。
Load ControInet Model
Load ControlNet Modelノードは、ControlNetモデルをロードするために使用できます。Apply ControlNetと併用します。
Load LoRA
Load VAE
Load Upscale Model
Load Checkpoint
Load Style Model
Load Style Modelノードは、スタイルモデルをロードするために使用できます。スタイルモデルは、拡散モデルにデノイズされた潜在画像がどのようなスタイルになるべきかについて視覚的なヒントを提供するために使用されます。
*現在サポートされているのはT2IAdaptorスタイルモデルのみです。
Hypernetwork Loader
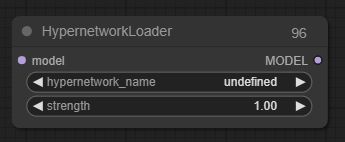
Hypernetwork Loaderノードは、ハイパーネットワークをロードするために使用できます。これはLoRAに似ており、拡散モデルを修正して潜在画像のノイズを除去する方法を変更します。一般的な使用例には、特定のスタイルで生成する能力をモデルに追加することや、特定の主題やアクションをよりよく生成する能力を追加することが含まれます。複数のハイパーネットワークを連鎖させてモデルをさらに修正することもできます。
Conditioning
Apply ControlNet
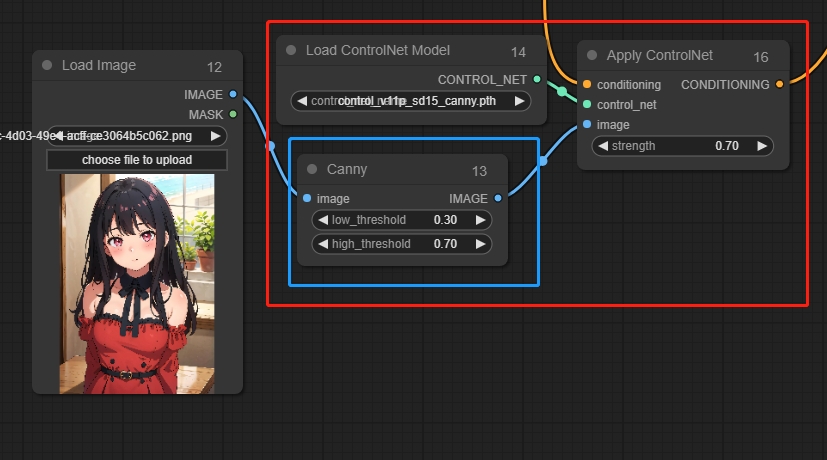
ControlNetモデルをロードし、複数のControlNetノードを接続できます。
パラメータ:
strength: 値が高いほど、画像に対する制約が強くなります。
*ControlNet画像は対応する前処理画像である必要があります。例えば、Canny前処理画像はCanny前処理グラフに対応します。したがって、元の画像とControlNetの間に対応するノードを追加して、前処理グラフに変換する必要があります。
CLIP Text Encode (Prompt)
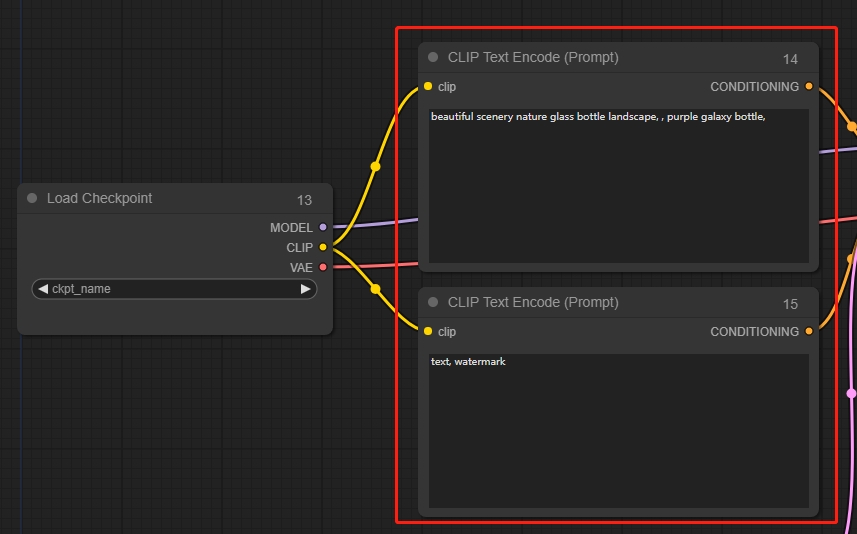
テキストプロンプトを入力し、肯定的なプロンプトと否定的なプロンプトを含みます。
CLIP Vision Encode
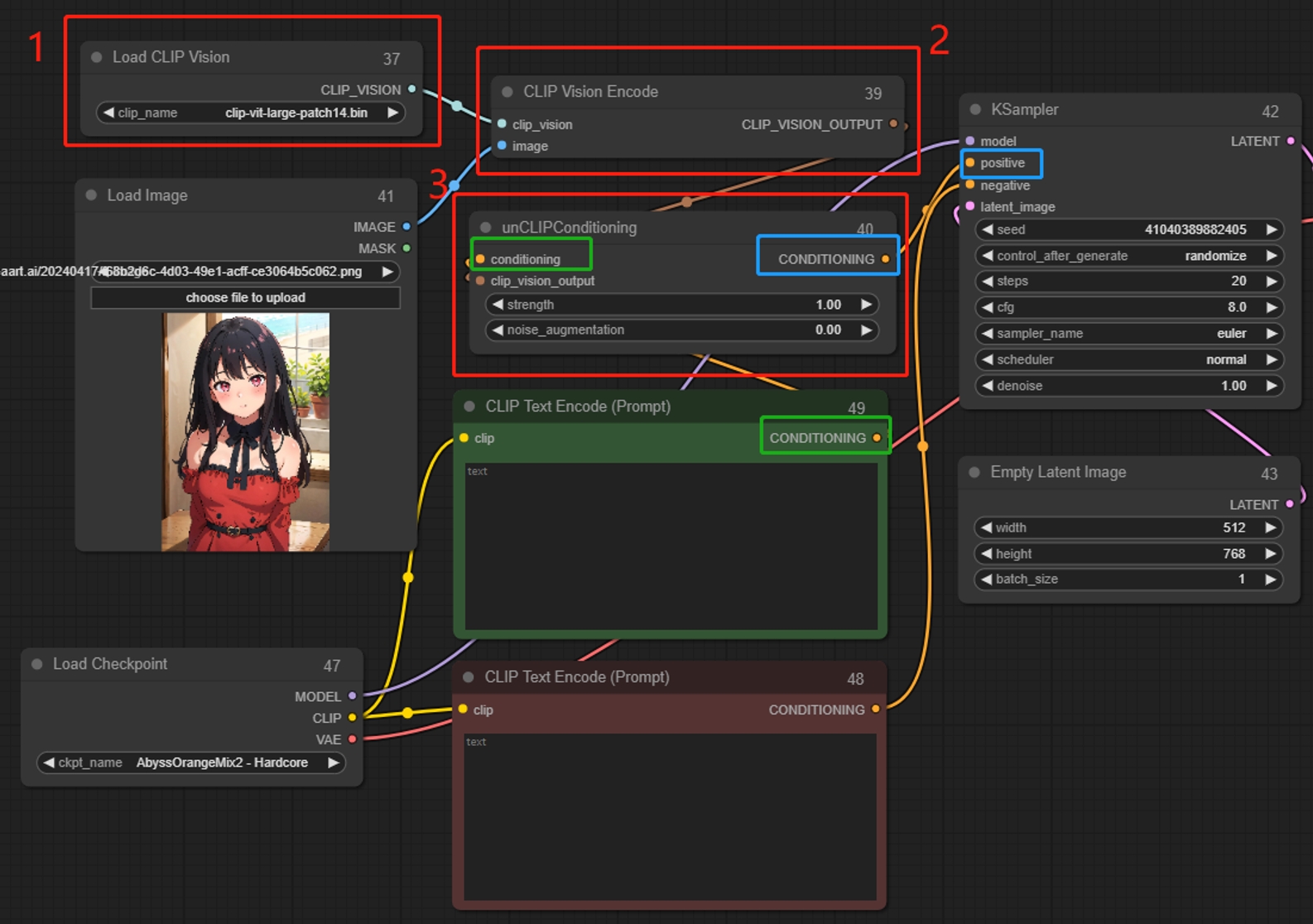
画像をデコードして説明(プロンプト)を生成し、それらをサンプラーの条件付き入力に変換します。デコードされた説明(プロンプト)に基づいて、新しい類似画像を生成します。複数のノードを一緒に使用できます。概念や抽象的なものを変換するのに適しており、Clip Vision Encodeと組み合わせて使用します。
CLIP Set Last Layer
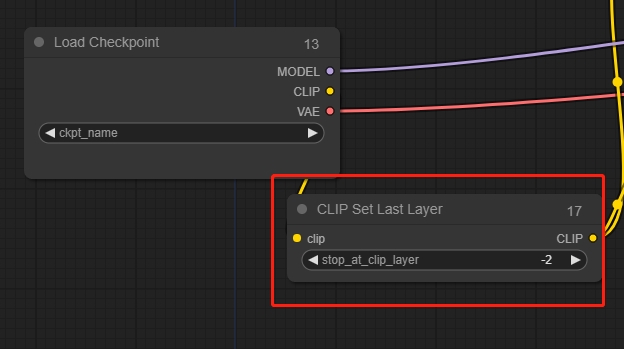
Clip Skip, 一般的には-2に設定します。
GLIGEN Textbox Apply
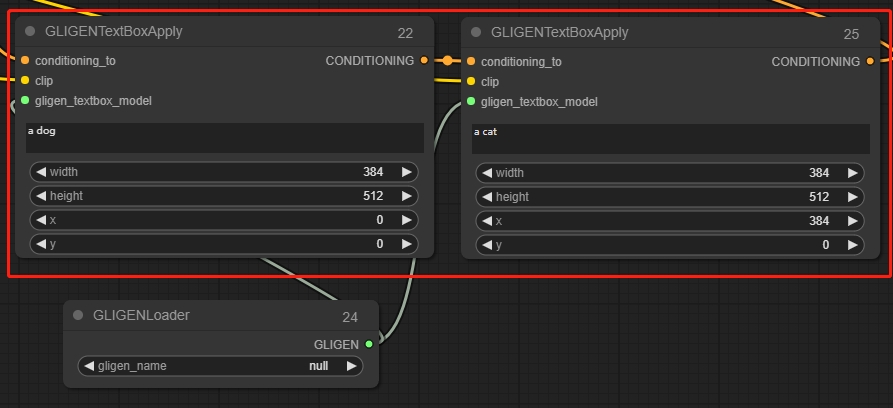
指定された画像の一部でプロンプトを生成するようにガイドします。
*ComfyUIの座標系の原点は左上隅にあります。
unCLIP Conditioning
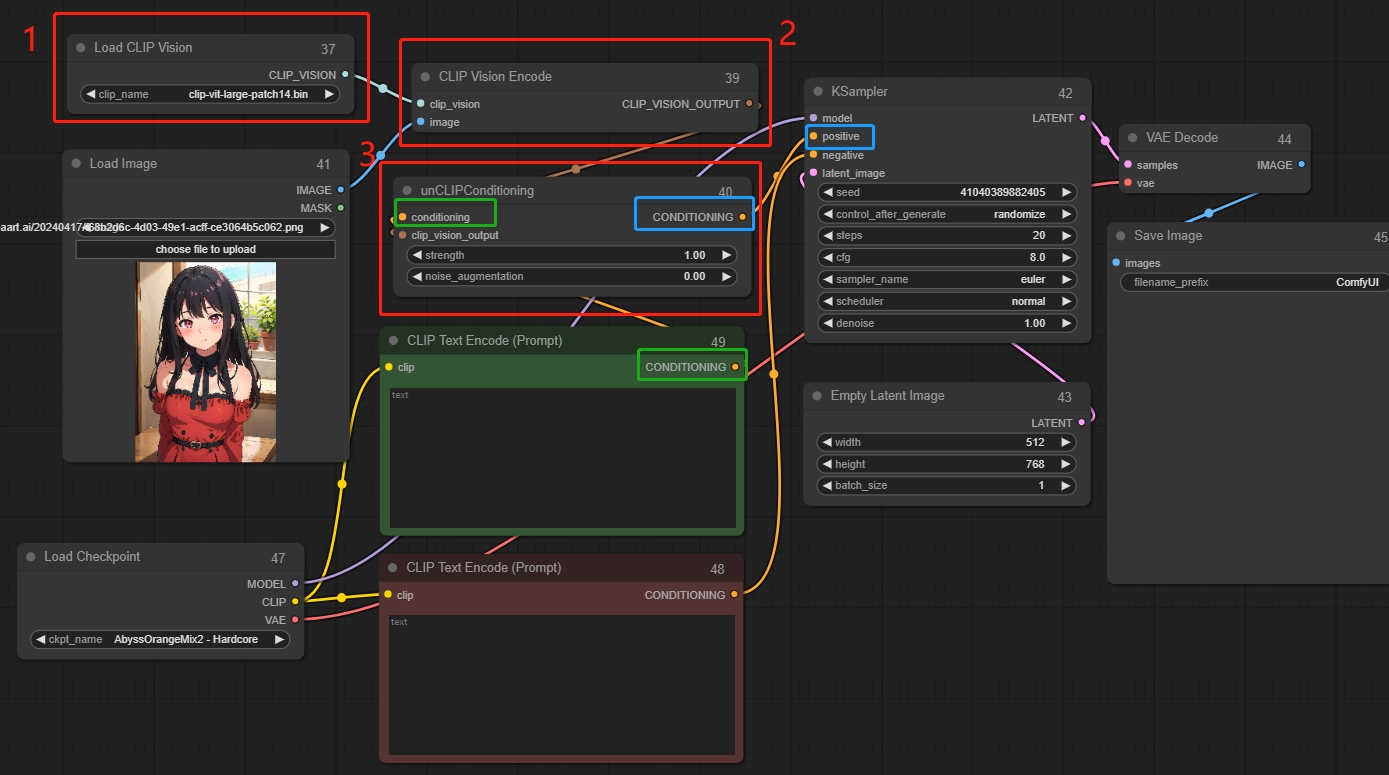
CLIPビジョンモデルを通じてエンコードされた画像は、unCLIPモデルに追加の視覚的ガイダンスを提供します。このノードは、複数の画像をガイダンスとして提供するために連鎖させることができます。
Conditioning Average
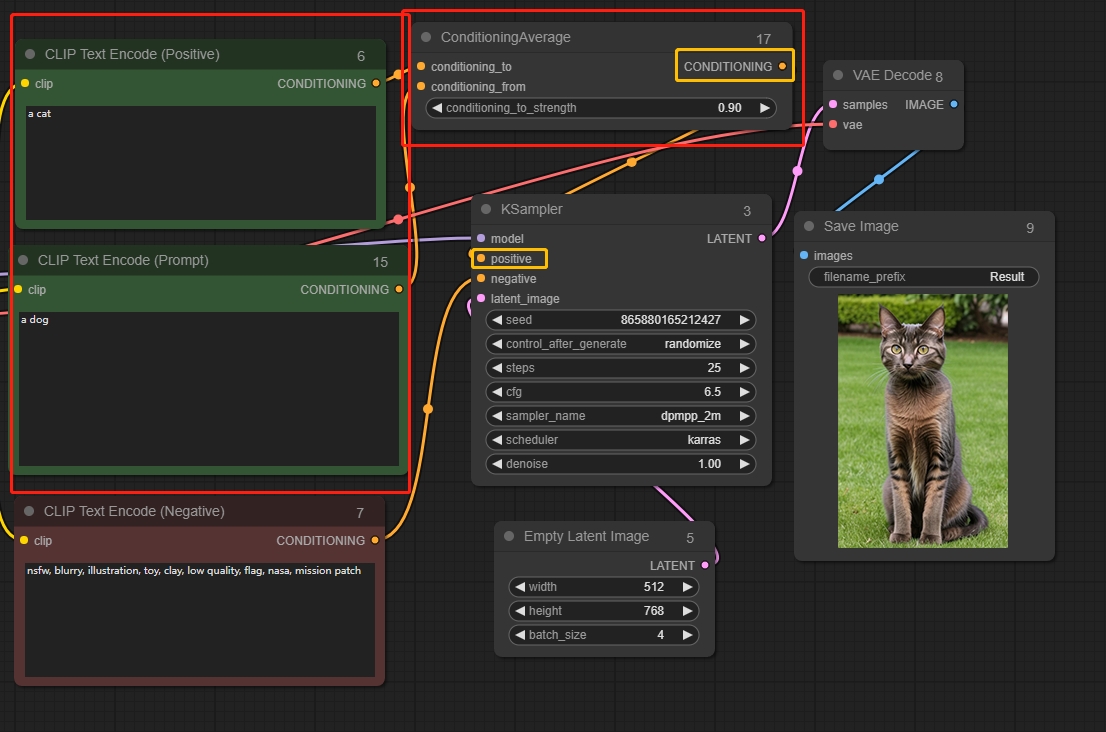
強度に基づいて2つの情報をブレンドします。
conditioning_to_strengthが1に設定されている場合、拡散はconditioning_toによってのみ影響されます。conditioning_to_strengthが0に設定されている場合、画像の拡散はconditioning_fromによってのみ影響されます。
Apply Style Model
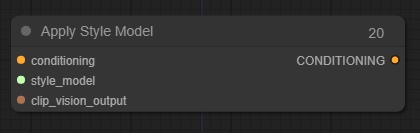
拡散モデルに追加の視覚的ガイダンスを提供するために使用できます。特に生成された画像のスタイルに関して。
Conditioning (Combine)
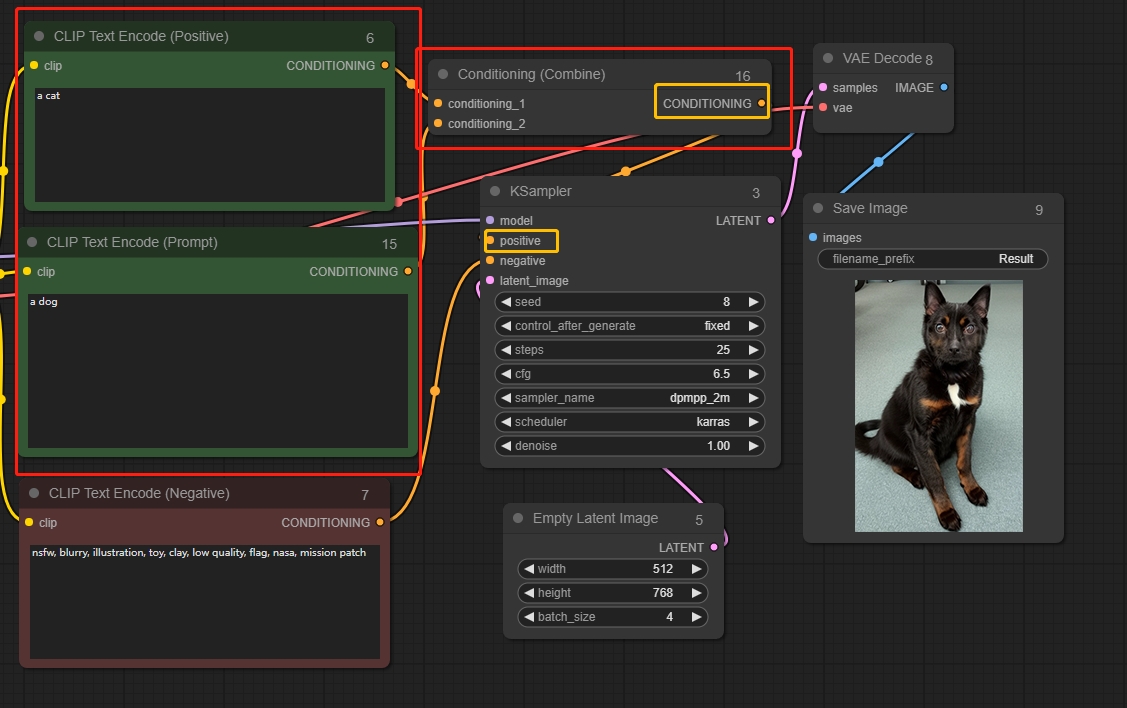
2つの情報をブレンドします。
Conditioning (Set Area)
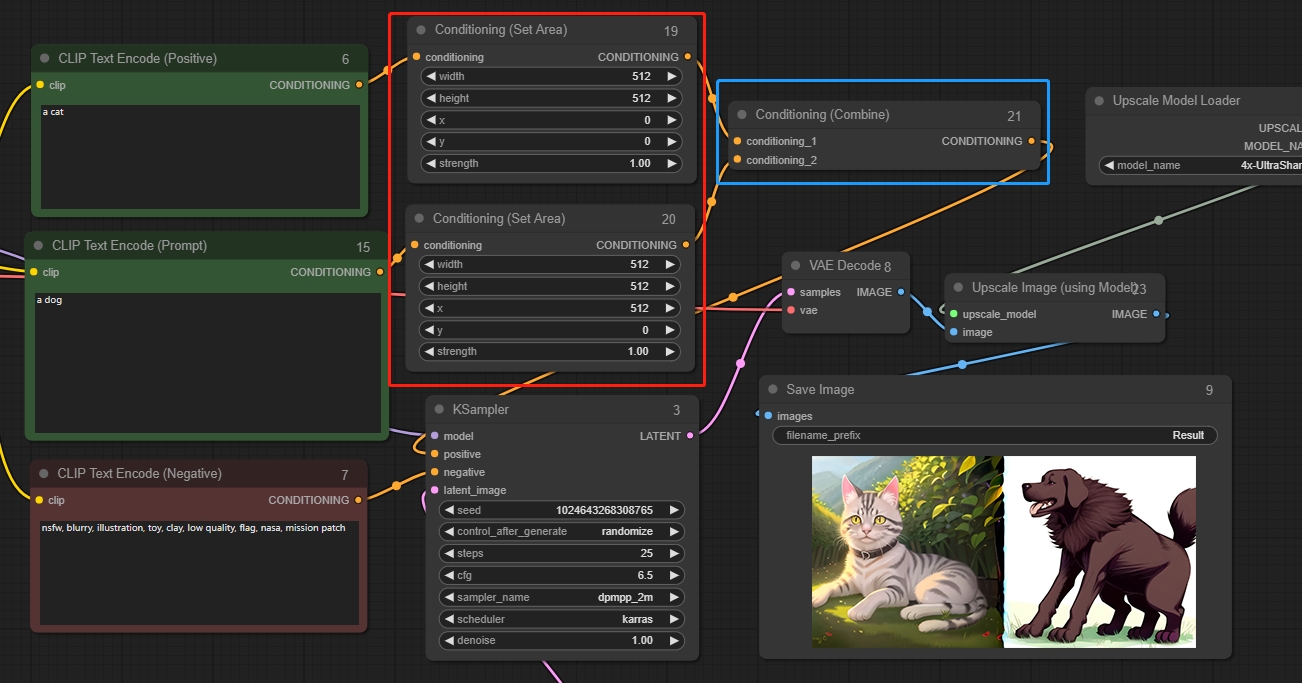
Conditioning (Set Area)は、画像の特定の領域内に影響を制限するために使用できます。Conditioning (Combine)と一緒に使用すると、最終画像の構成をよりよく制御できます。
パラメータ:
width: 制御領域の幅
height: 制御領域の高さ
x: 制御領域の原点のx座標
y: 制御領域の原点のy座標
strength:条件情報の強度
*ComfyUIの座標系の原点は左上隅にあります。
図に示すように、左側を「猫」、右側を「犬」に設定します。
Conditioning (Set Mask)
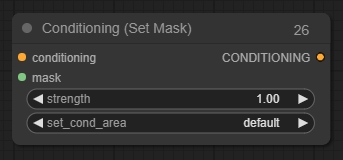
Conditioning (Set Mask)は、特定のマスク内で調整を制限するために使用できます。Conditioning (Combine)ノードと一緒に使用すると、最終画像の構成をよりよく制御できます。
Latent
VAE Encde(for Inpainting)
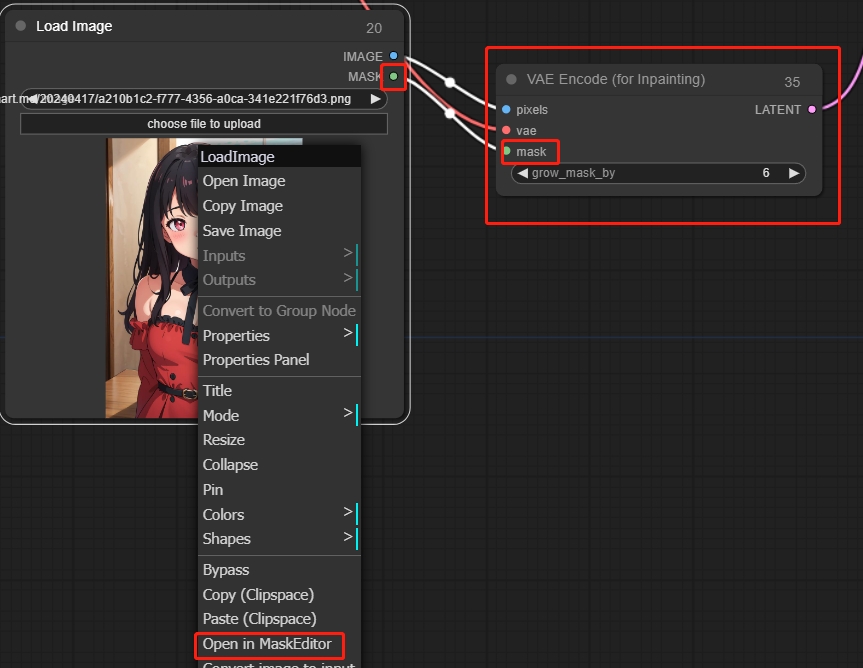
部分再描画に適用され、右クリックしてMaskEditorで開くことで部分再描画を実現します。
Set Latent Noise Mask
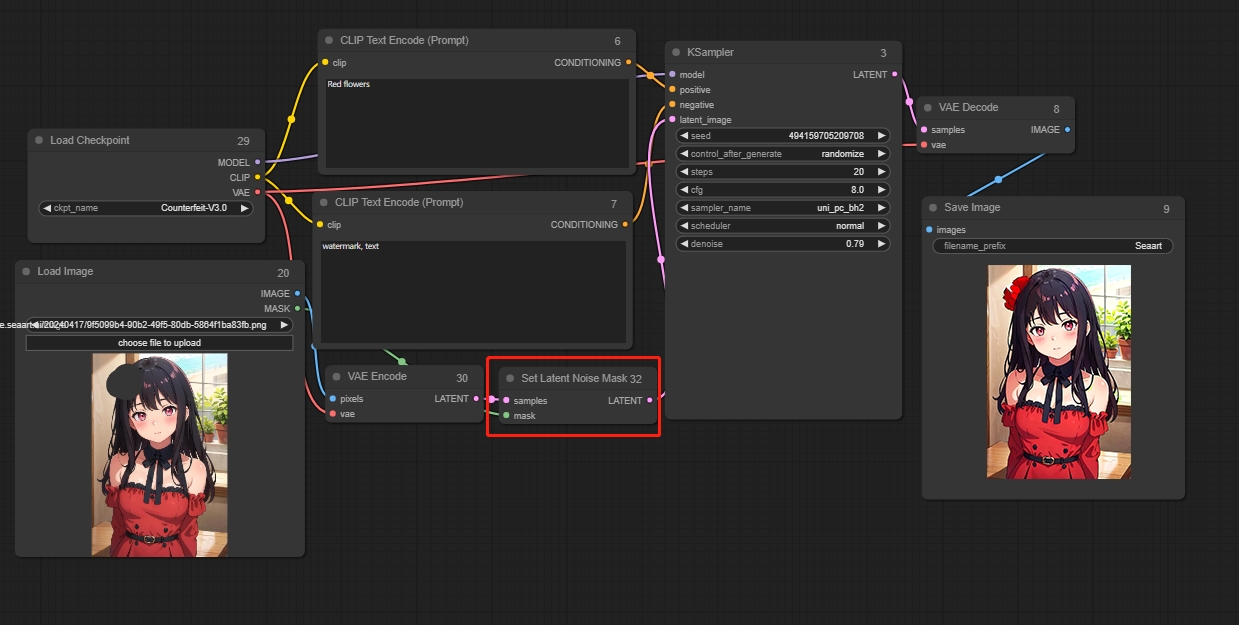
部分再描画の第二の方法は、まずVAEエンコーダーを通じて画像をエンコードし、それを潜在空間で認識可能なコンテンツに変換します。次に、マスクされた部分を潜在空間で再生成します。
VAEエンコード(インペイント用)メソッドと比較して、このアプローチは再生成する必要があるコンテンツをよりよく理解できるため、誤った画像が生成される確率が低くなります。再描画する画像を参照します。
Rotate Latent
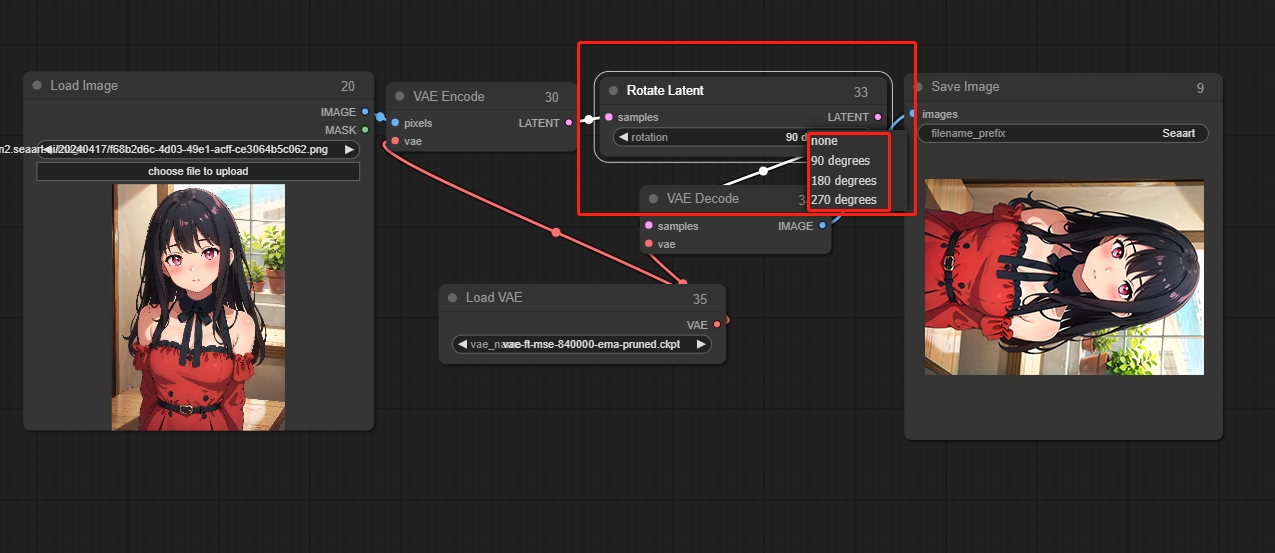
画像を時計回りに回転します。
Flip Latent
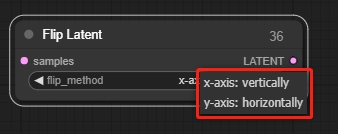
画像を水平または垂直に反転します。
Crop Latent
画像を新しい形状にクロップするために使用されます。
VAE Encode
VAE Decode
Latent From Batch
バッチから潜在画像を抽出します。Latent From Batchノードは、バッチから潜在画像または画像セグメントを選択するために使用できます。これは、特定の潜在画像または画像を分離する必要があるワークフローで非常に役立ちます。
パラメータ:
batch_index: 最初に選択する潜在画像のインデックス。
length: 取得する潜在画像の数。
Repeat Latent Batch
画像のバッチを繰り返すことができ、IMG2IMGワークフローで画像の複数のバリエーションを作成するのに便利です。
パラメータ:
amount: 繰り返しの回数。
Rebatch Latents
潜在空間画像のバッチを分割または結合するために使用できます。
Upscale Latent
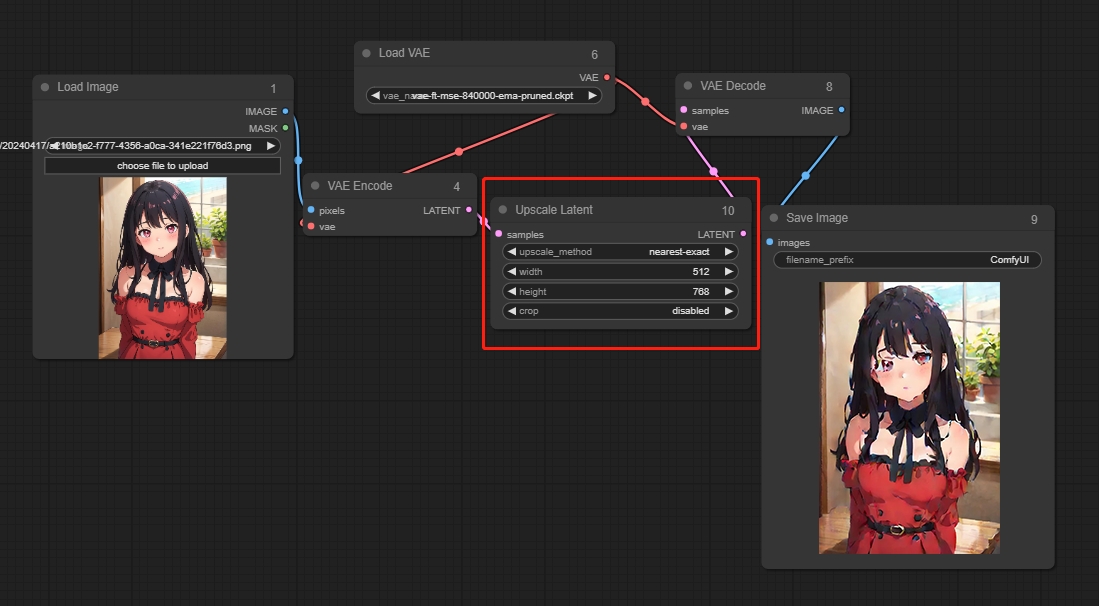
潜在空間画像の解像度を調整し、ピクセルフィリングを行います。
パラメータ:
upscale_method: ピクセルフィリングの方法。
width: 調整された潜在空間画像の幅。
height: 調整された潜在空間画像の高さ。
crop: 画像をクロップするかどうかを示します。
*潜在空間の画像をアップスケールすると、VAEを通じてデコードされる際に劣化する可能性があります。KSamplerを使用して二次サンプリングを行い、画像を修復できます。
Latent Composite
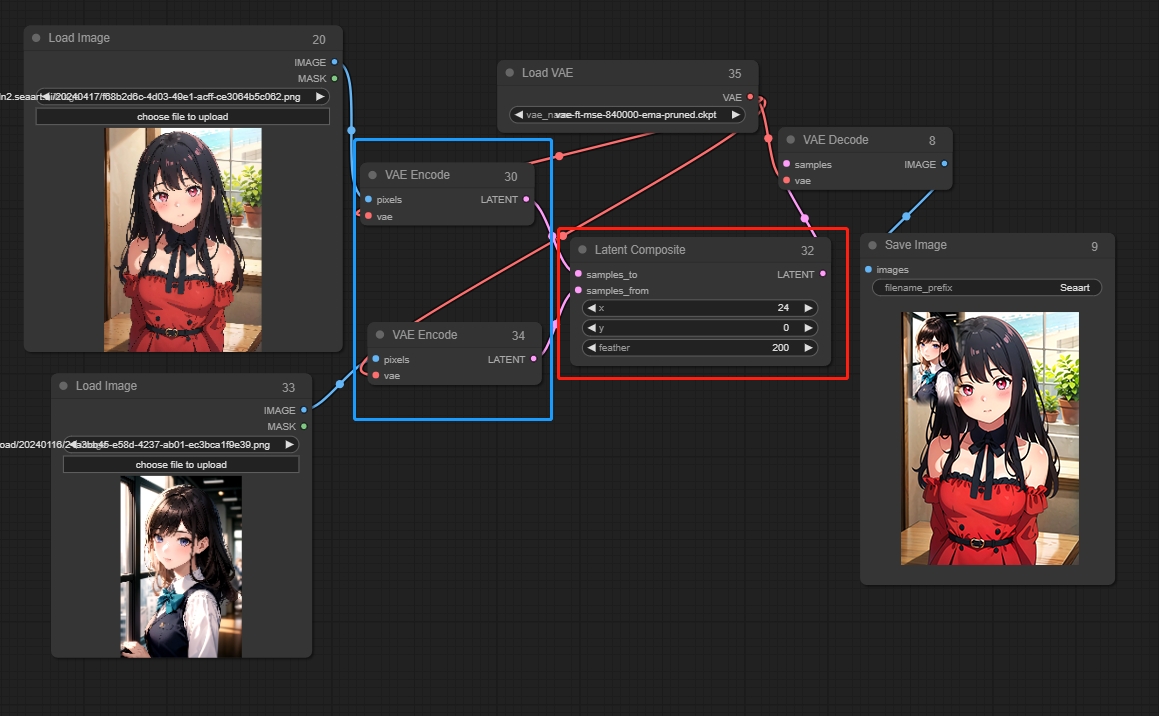
一つの画像を別の画像にオーバーレイします。
パラメータ:
x: 上層のオーバーレイ位置のx座標。
y: 上層のオーバーレイ位置のy座標。
feather: エッジのフェザリングの度合いを示します。
*画像は潜在空間にエンコード(VAEエンコード)される必要があります。
Latent Composite Masked
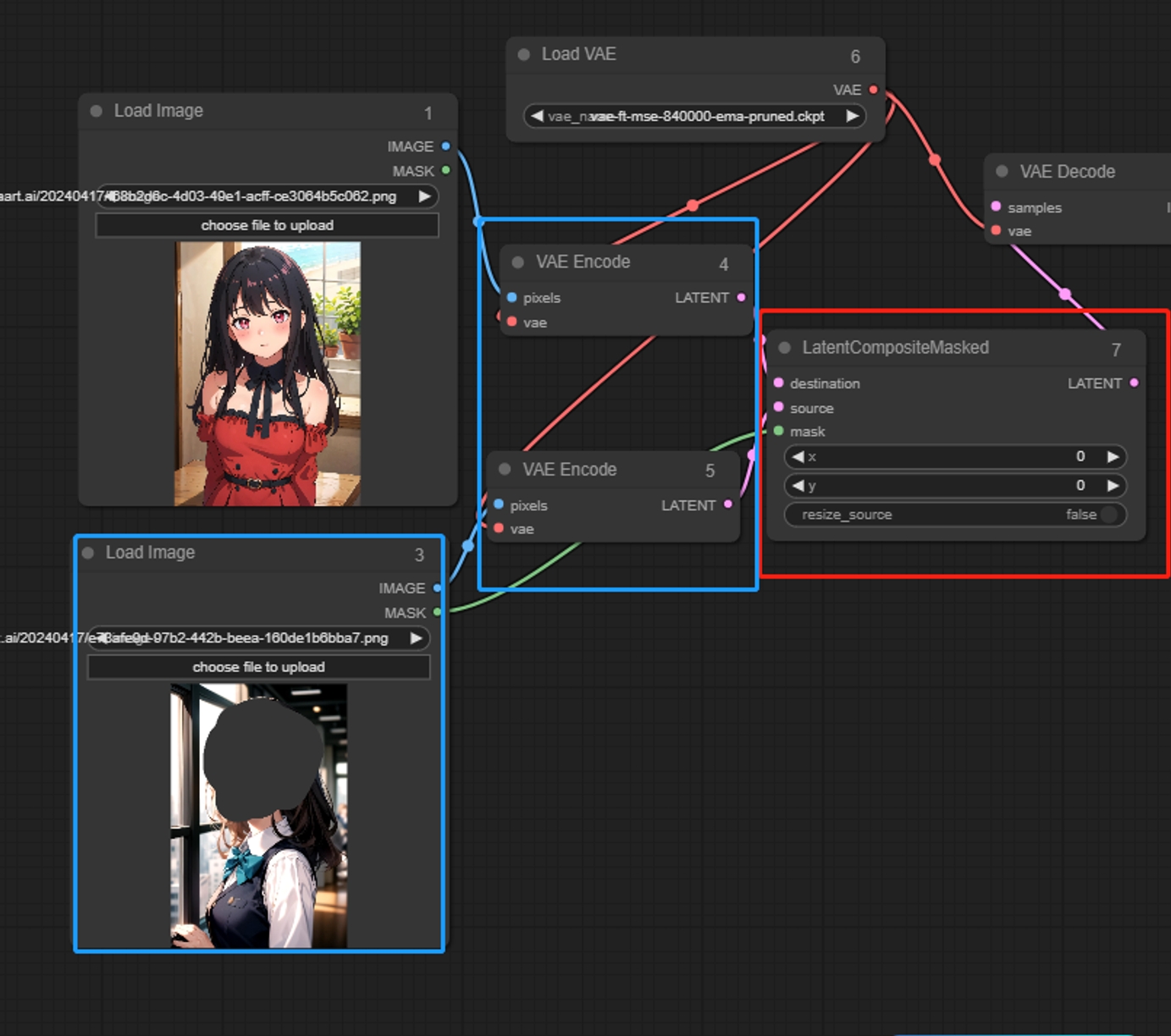
マスクを使用して一つの画像を別の画像にオーバーレイし、マスクされた部分のみをオーバーレイします。
入力:
destination: 基礎となる潜在空間画像。
source: オーバーレイする潜在空間画像。
Parameters:
x: オーバーレイ領域のx座標。
y: オーバーレイ領域のy座標。
resize_source: マスクされた領域の解像度を調整するかどうかを示します。
Empty Latent Image
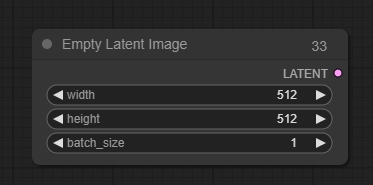
Empty Latent Imageは、新しい空の潜在画像のセットを作成するために使用できます。これらの潜在画像は、ノイズを追加し、サンプリングノードを使用してそれらをノイズ除去することにより、Text2Imgなどのワークフローで使用できます。
Mask
Load Image As Mask
Invert Mask
Solid Mask
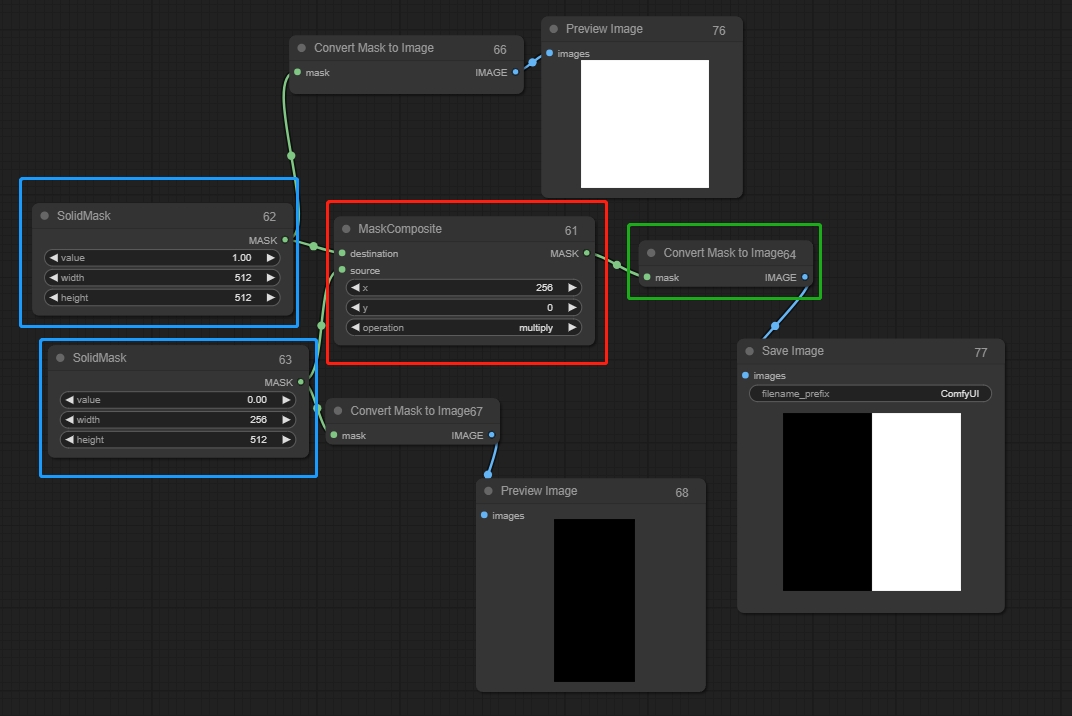
画像生成のキャンバスとして機能し、マスク合成と組み合わせることができます。
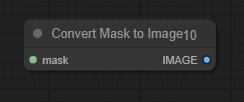
Convert Mask To Image
Convert Image To Mask
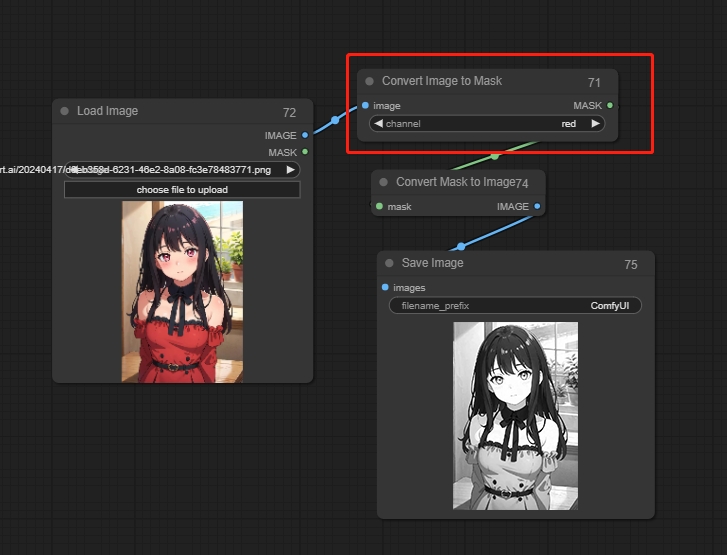
マスクをグレースケール画像に変換します。
Feather Mask
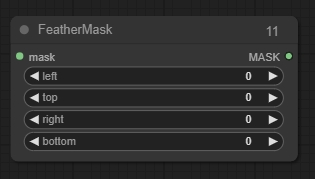
マスクにフェザリングを適用します。
Crop Mask
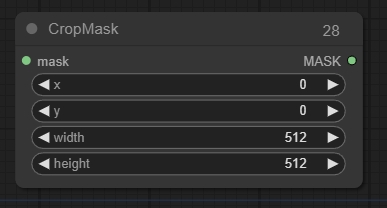
マスクを新しい形状にクリップします。
Mask Composite
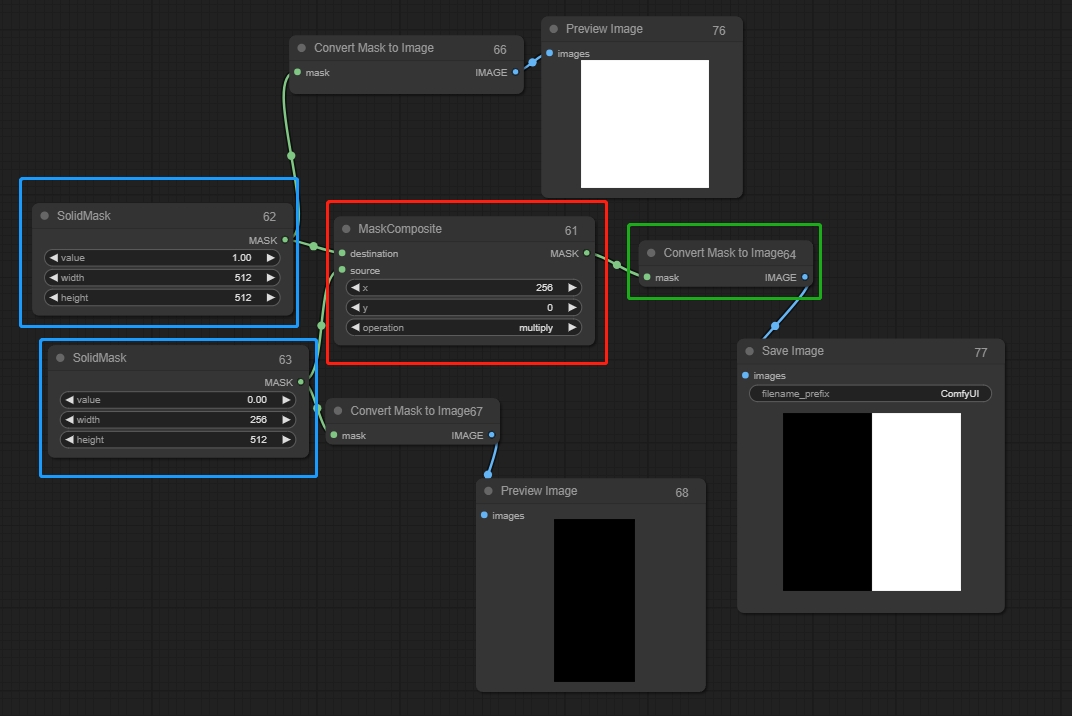
一つのマスクを別のマスクに貼り付け、ソリッドマスクを接続します。値が0は黒を表し、描画されず、値が1は白を表し、描画されます。接続された二つのソリッドマスクの値は異なる必要があります。そうでなければ、マスクは効果を発揮しません。
入力:
destination(1): 貼り付けるマスク、最終画像の寸法に相当します。
source(0): 貼り付けるマスク。
パラメータ:
X,Y: ソースの位置を調整します。
operation: ソースが0の場合は乗算、1の場合は加算を使用します。
Sampler
KSampler
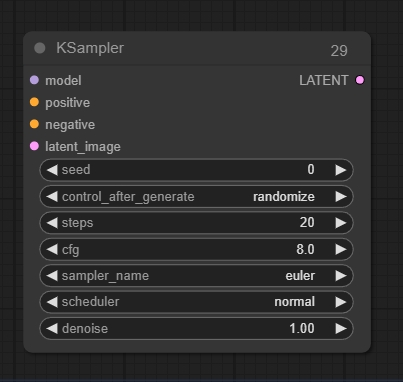
入力:
latent_image: ノイズ除去される潜在画像。
出力:
LATENT: ノイズ除去後の潜在画像。
KSampler Advanced
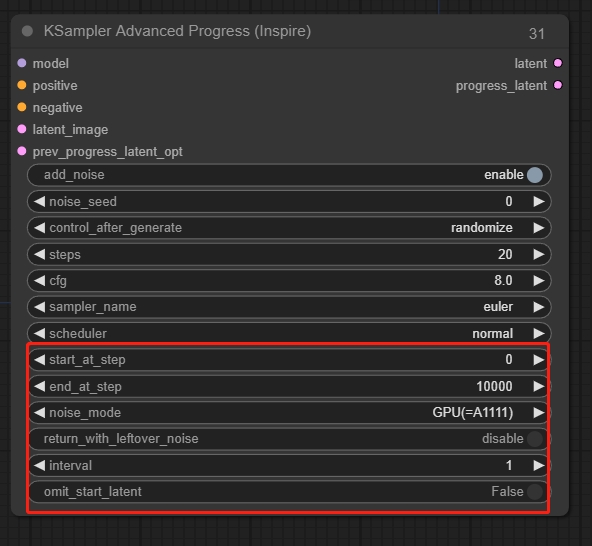
ノイズを手動で制御できます。
高度なノード
Load Checkpoint With Config
提供された設定ファイルに基づいて拡散モデルをロードします。
その他のノード(継続的に更新中)
AIO Aux Preprocessor
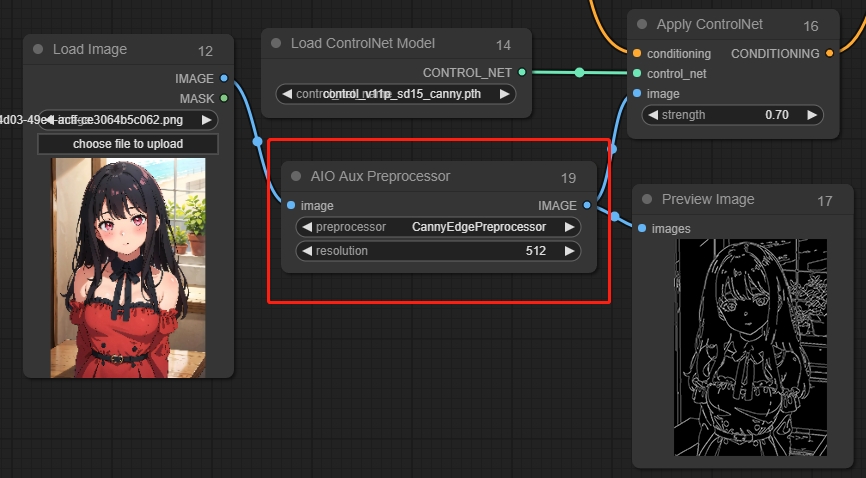
異なる前処理プロセッサを選択して対応する画像を生成します。
Last updated