核心节点
了解 ComfyUI 用于图像处理、调节等的核心节点。搭建ComfyUI工作流
Image 图像
Pad Image for Outpainting(扩展图像)
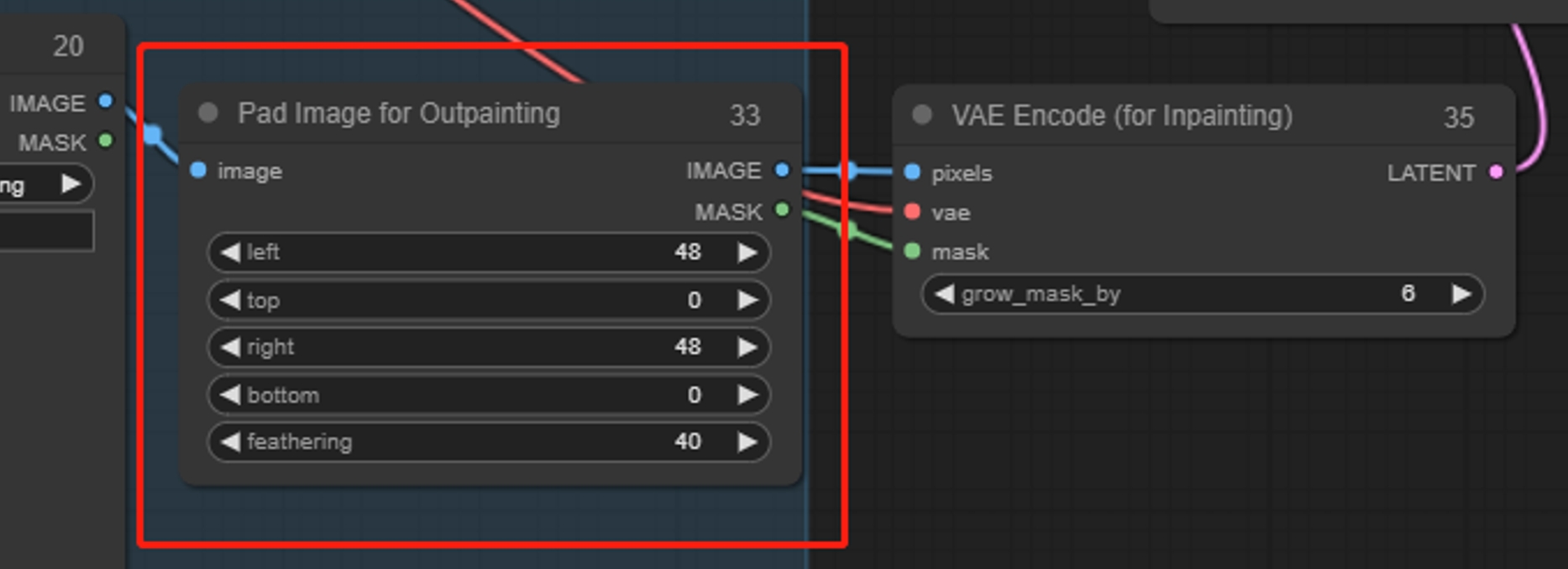
填充扩展图像,类似智能扩图,先增加图片尺寸,再将扩充区域作为蒙版进行绘制,建议搭配VAE Encode(for Inpainting)节点,保证原始图像不会变化
参数:
left、top、right、bottom:上下左右的填充量
feathering:边缘羽化程度
Save Image(保存图像)
Load Image(加载图像)
ImageBlur(图像模糊)
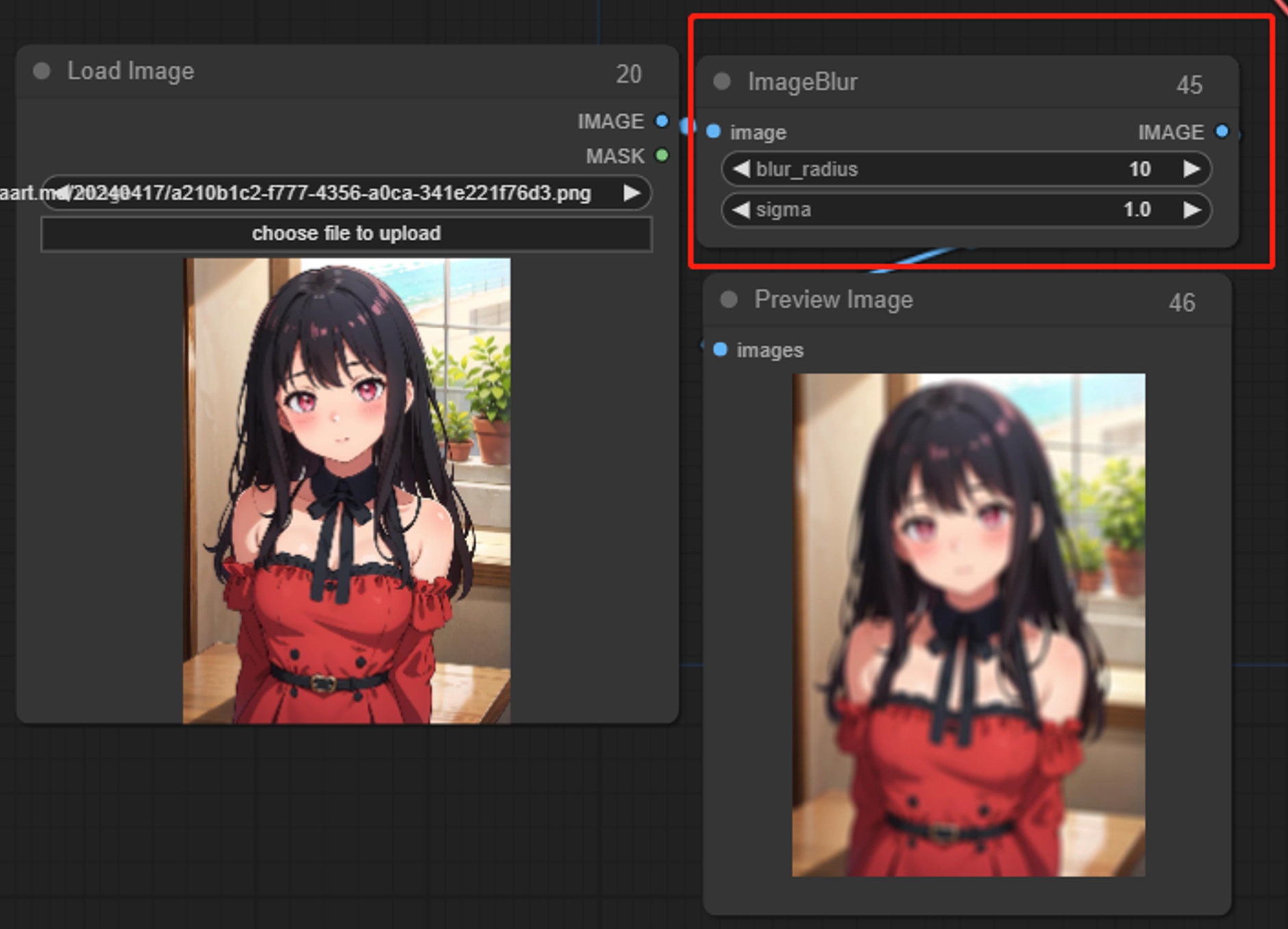
为图像加上模糊的效果
参数:
sigma:值越小,模糊就越集中于中心像素
Image Blend(图像混合)
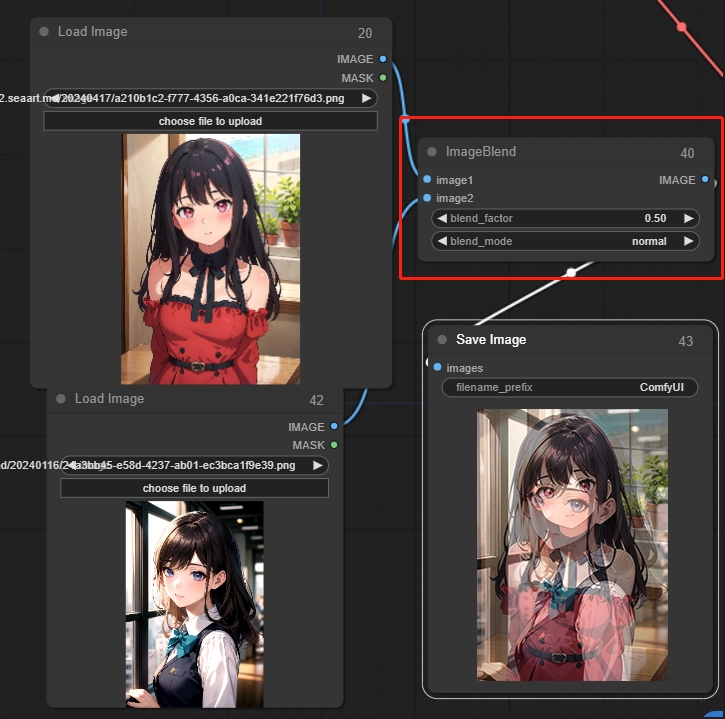
可以通过透明度将两张图像混合
参数:
blend_factor:第二个图像的不透明度
blend_mode:图像混合的方式
Image Quantize(图像量化)
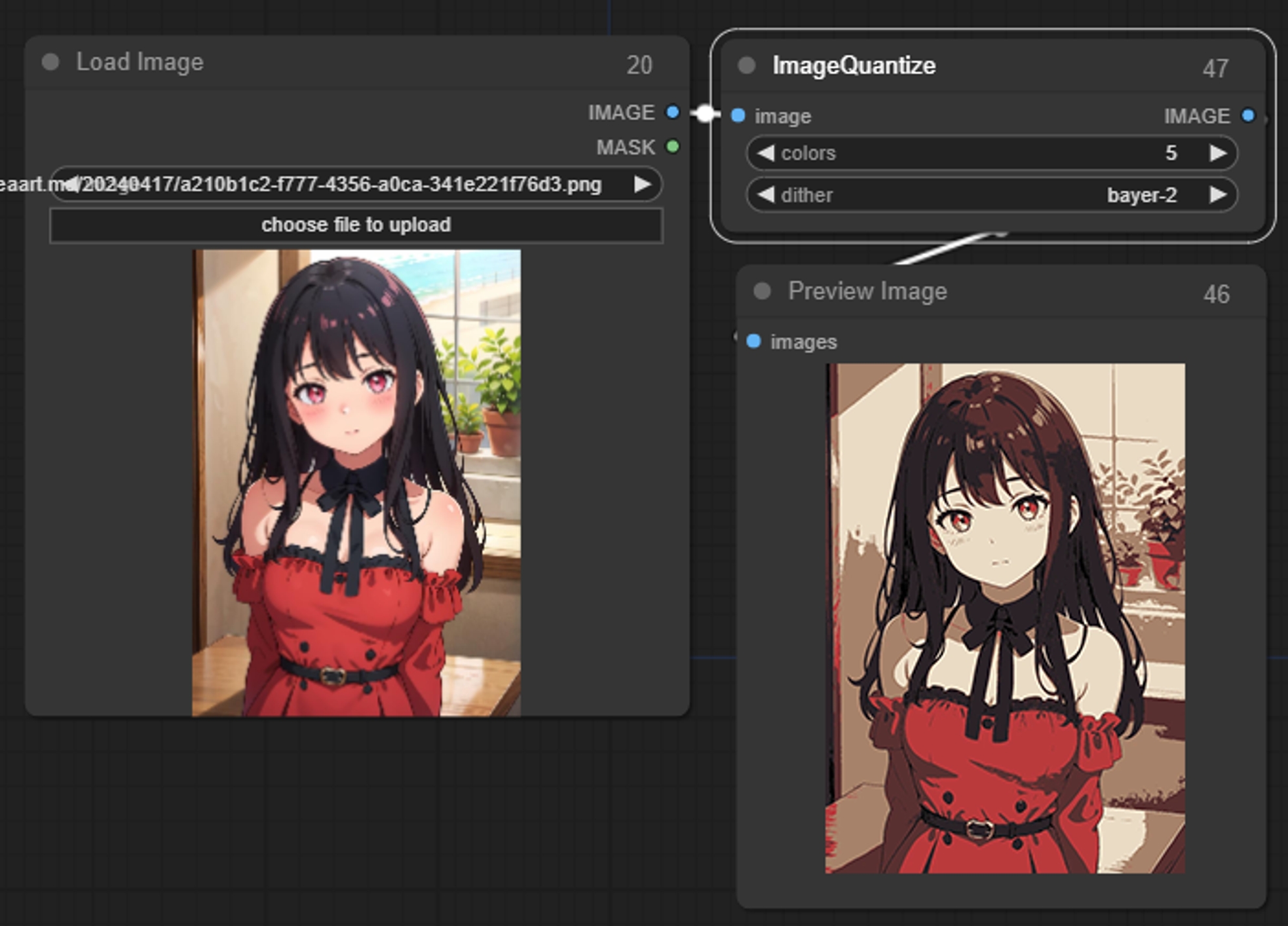
减少图像中的颜色数量
参数:
colors:量化图像中的颜色数量,当为1时,图像只有一个颜色
dither:是否使用抖动使量化图像看起来更平滑
Image Sharpen(图像锐化)
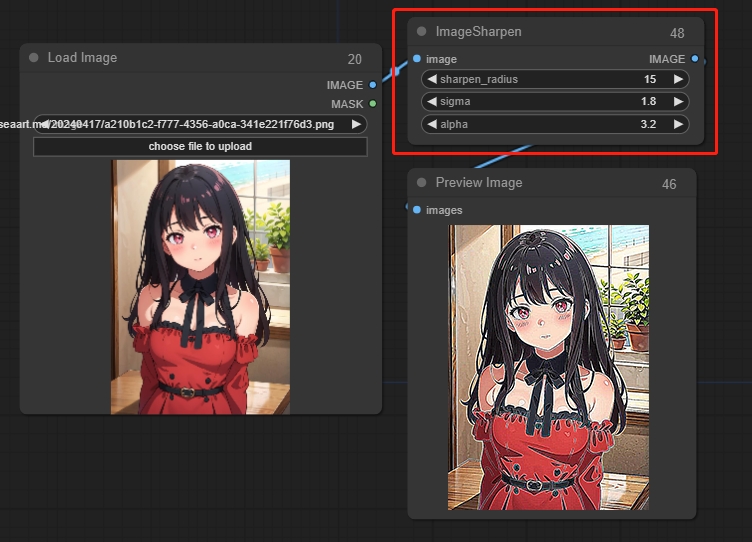
参数:
sigma:值越小,锐化就越集中于中心像素
alpha:锐化的强度
Invert Image(图像反转)
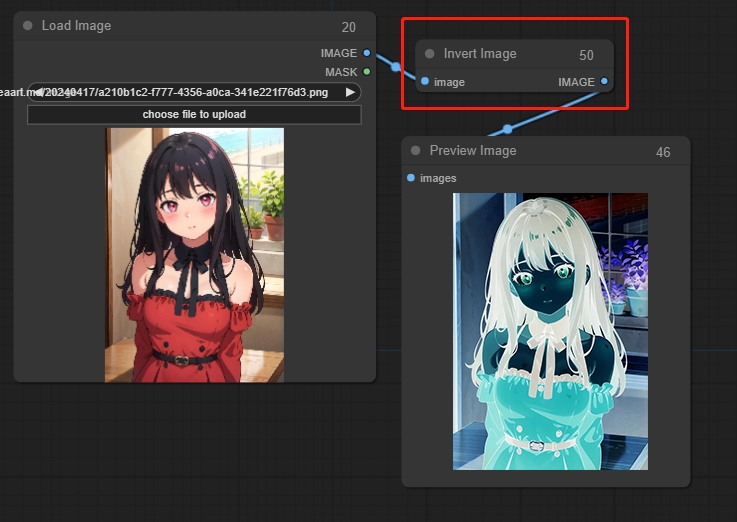
反转图像的颜色
Upscaling(图像放大)
9.1 使用模型放大: Upscale Image (Using Model)
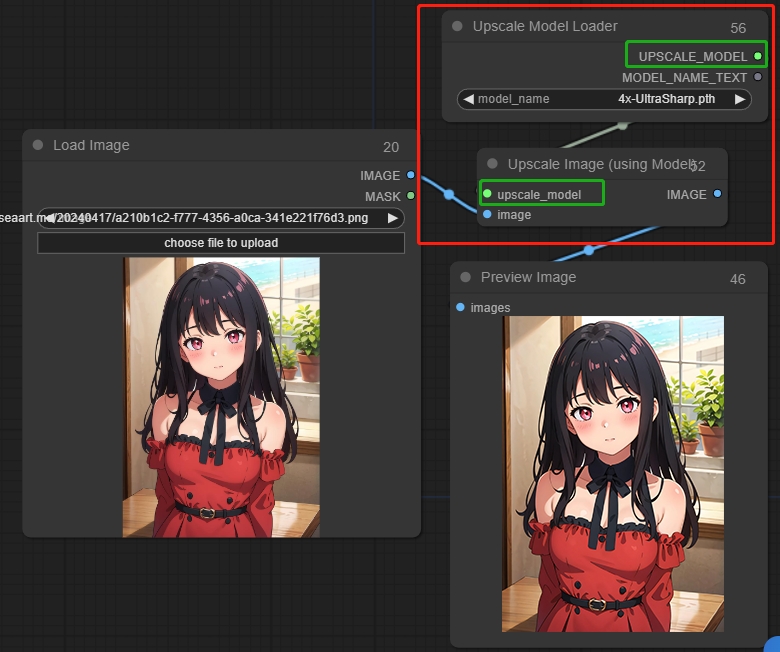
9.2 图像放大:Upscale Image
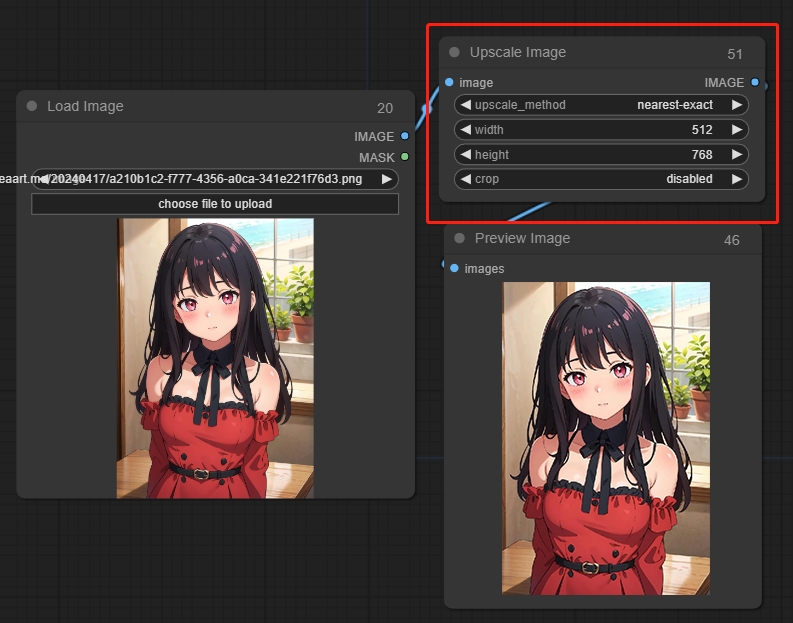
参数:
upscale_method:选择像素填充方法
width:调整后的图像宽度
height:调整后的图像高度
crop:是否对图片进行裁剪
Preview Image(预览图像)
Loaders 加载器
Load CLIP Vision(视觉模型节点)
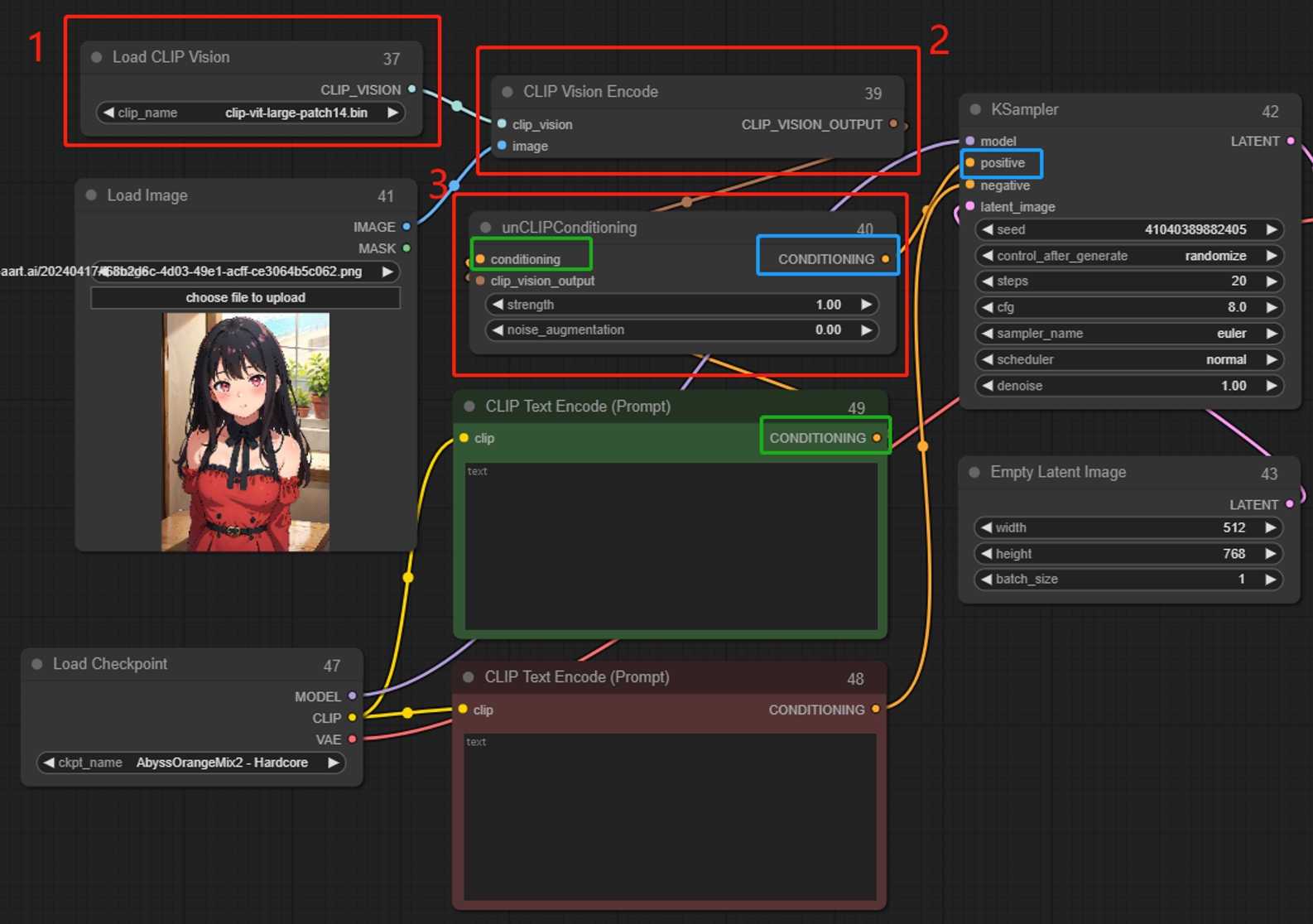
将图片解码形成描述(提示词),最后再转换为条件输入到采样器,根据解码到的描述(提示词),生成新的类似图片,可以多个节点一起使用。适合转换概念、抽象的东西,搭配Clip Vison Encode使用
Load CLIP(CLIP 节点)
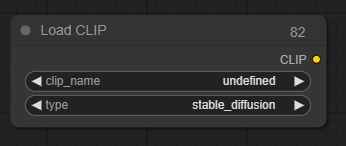
Load CLIP节点可用于加载特定的CLIP模型,CLIP模型用于编码指导扩散过程的文本提示。
*条件扩散模型是使用特定的CLIP模型进行训练的,使用与其训练所用模型不同的模型不太可能产生良好的图像。Load Checkpoint节点会自动加载正确的CLIP模型。
unCLIP Checkpoint Loader(检查点加载器节点)
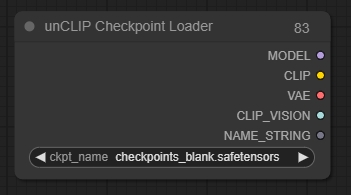
unCLIP检查点加载器节点可用于加载专门用于与unCLIP配合使用的扩散模型。unCLIP扩散模型用于去噪潜在特征,不仅提供文本提示,还包括提供的图像。该节点还将提供适当的VAE和CLIP及CLIP视觉模型。
*尽管此节点可用于加载所有扩散模型,但并非所有扩散模型都与unCLIP兼容。
Load ControInet Model(模型节点)
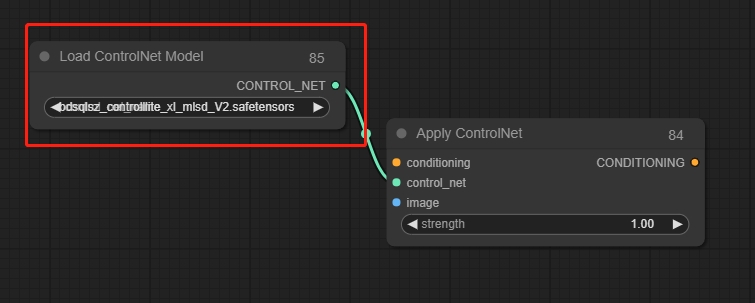
Load ControlNet Model节点可用于加载ControlNet模型,与Apply ControlNet配合使用。
Load LoRA(LoRA 节点)
Load VAE(VAE 节点)
Load Upscale Model(放大模型节点)
Load Checkpoint(加载大模型)
Load Style Model(风格模型节点)
Load Style Model节点可用于加载风格模型。风格模型可用于向扩散模型提供视觉提示,指示去噪潜在特征应该具有何种风格。
*当前仅支持T2IAdaptor风格模型
Hypernetwork Loader(网络加载器节点)
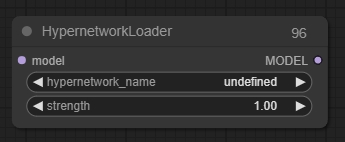
Hypernetwork Loader节点可用于加载超网络。与LoRAs类似,它们用于修改扩散模型,改变潜在特征去噪的方式。典型用法包括向模型添加以特定风格生成的能力,或更好地生成特定主题或动作。甚至可以将多个超网络链接在一起,进一步修改模型。
Conditioning 条件假设
Apply ControlNet(应用ControlNet节点)
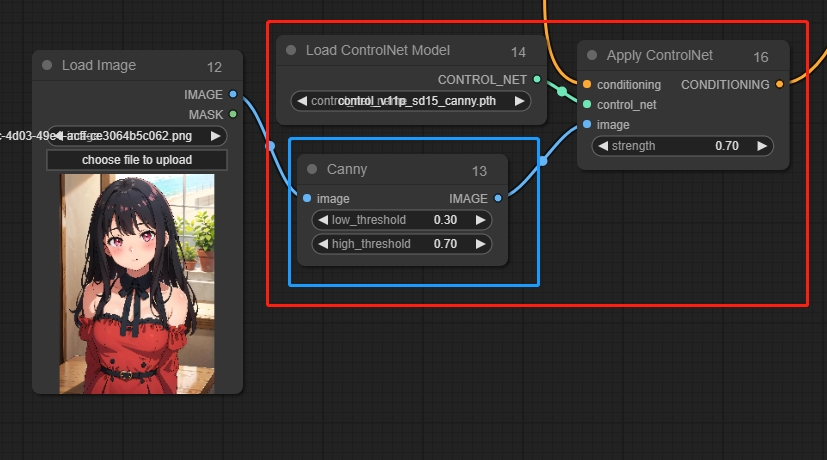
加载ControlNet模型,可以连接多个控制网节点
参数:
strength:权重程度,数值越高对图片约束越强
*控制网图像应该是相应的预处理图,例如canny对应canny的预处理图,因此需要在原始图像与控制网之间添加相应节点将其处理为预处理图
CLIP Text Encode (Prompt)(文本编码节点 )
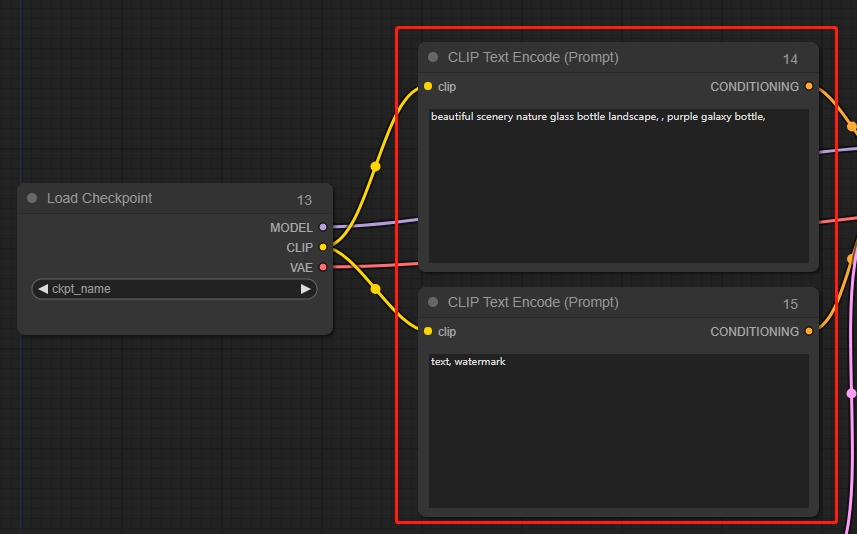
输入文本提示词,包括正向提示词和负向提示词
CLIP Vision Encode(CLIP 视觉编码节点)
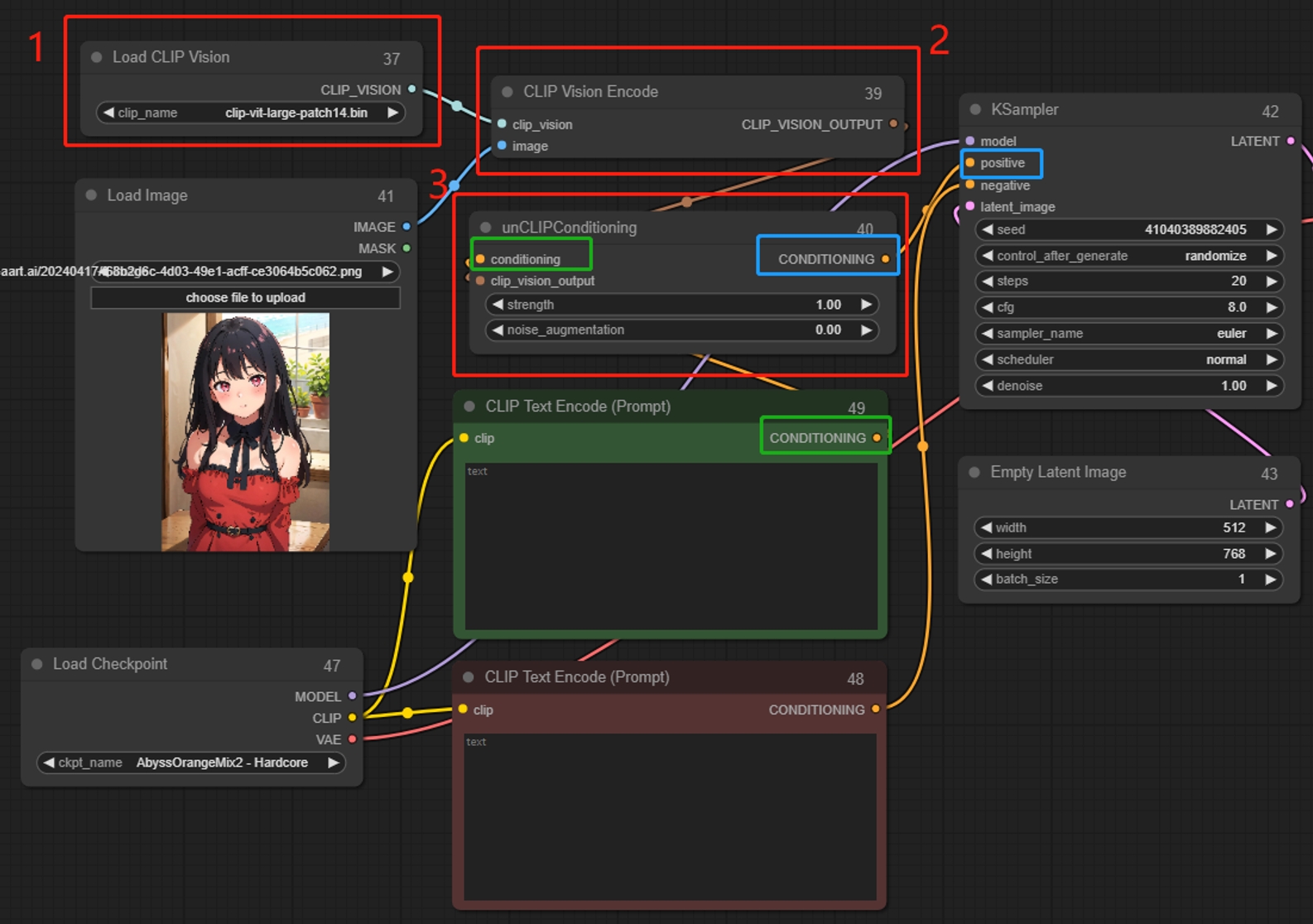
将图片解码形成描述(提示词),最后再转换为条件输入到采样器,根据解码到的描述(提示词),生成新的类似图片,可以多个节点一起使用。适合转换概念、抽象的东西,搭配Load Clip Vision使用
CLIP Set Last Layer(CLIP 设置最后一层节点)
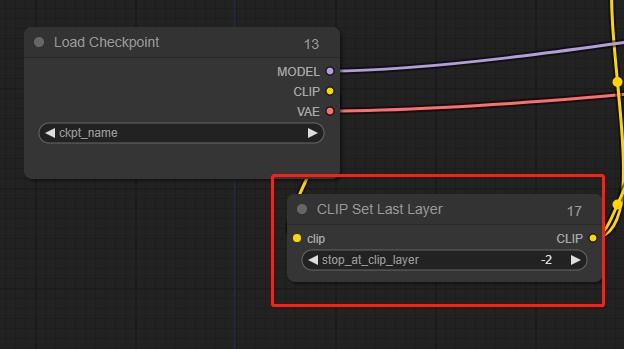
Clip Skip,通常设置为-2
GLIGEN Textbox Apply(GLIGEN文本框应用节点)
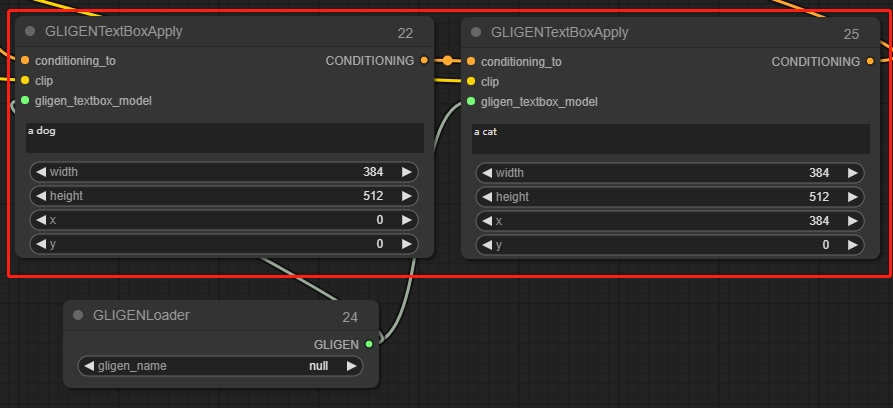
引导提示词在图像的指定部分生成
*ComfyUI中坐标系统的原点位于左上角
unCLIP Conditioning(unCLIP条件化节点)
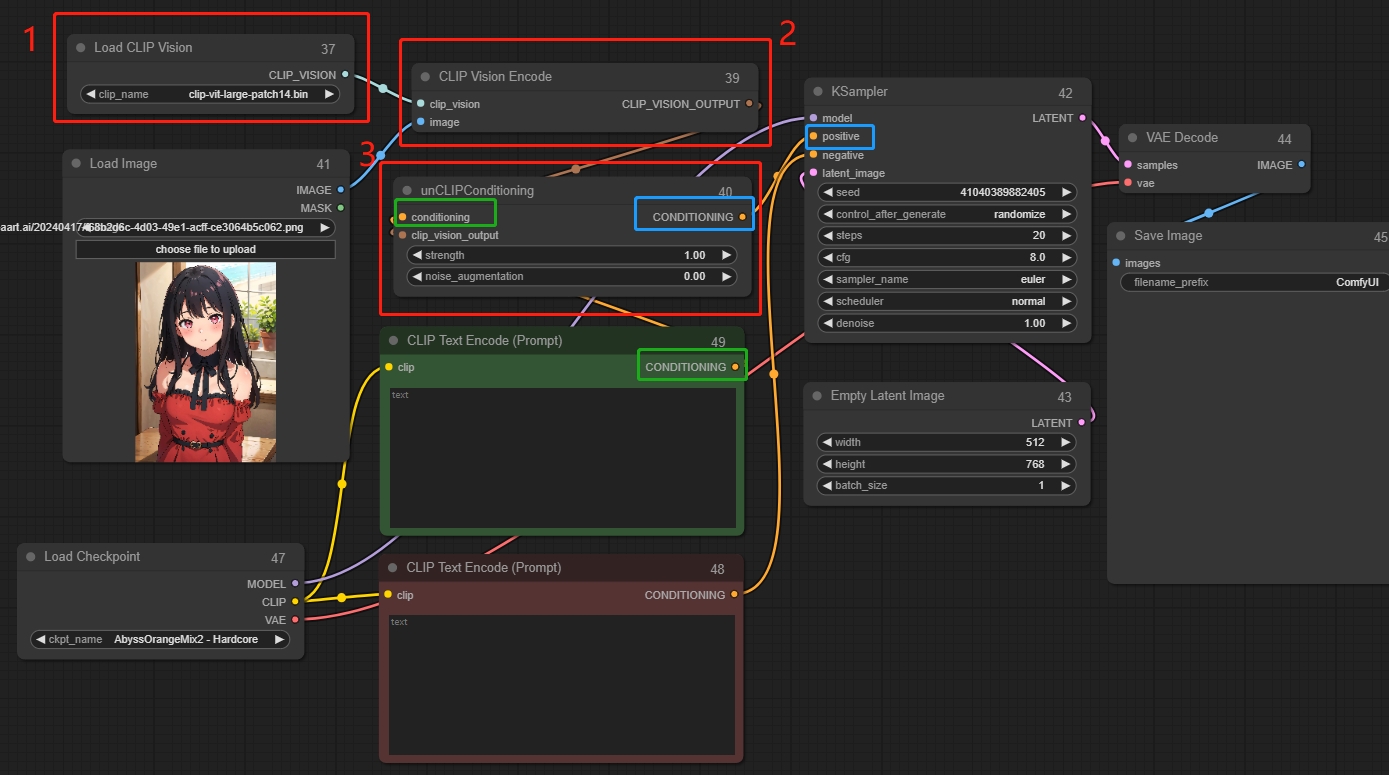
通过CLIP视觉模型编码的图像为unCLIP模型提供额外的视觉指导,此节点可以串联以提供多个图像作为指导
Conditioning Average(平均调节节点)
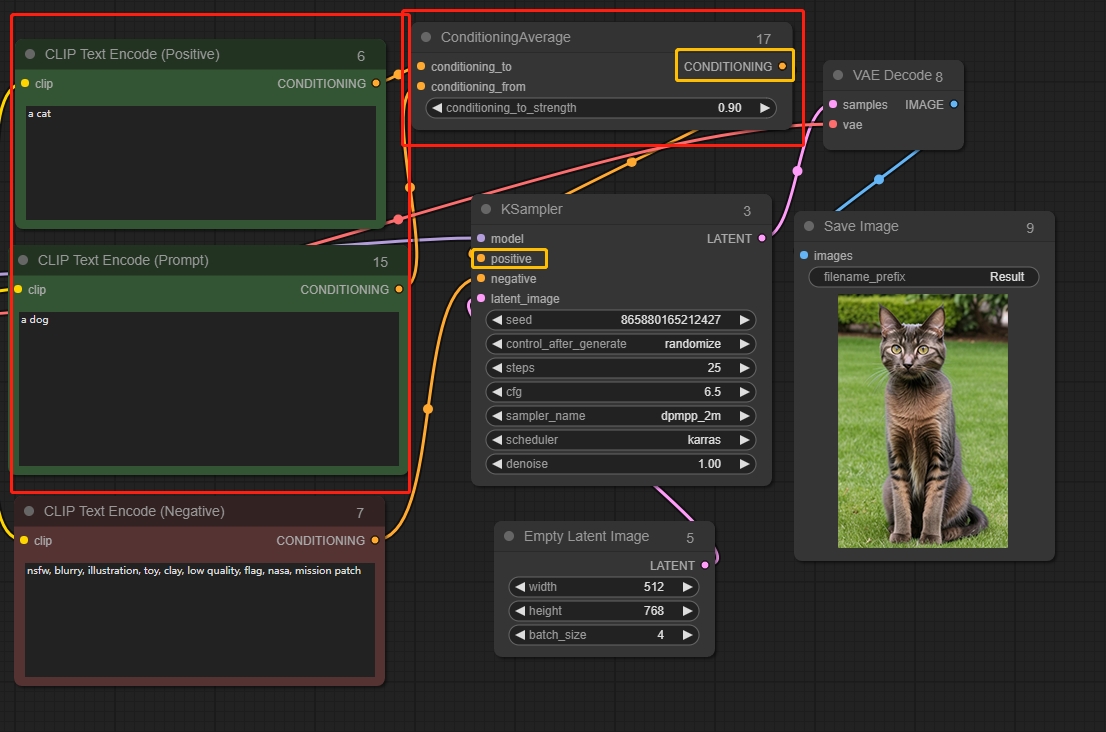
根据强度对两条信息进行混合,当conditioning_to_strngth为1时,扩散将只受conditioning_to的影响,当conditioning_to_strngth为0时,图像扩散将只受conditioning_from的影响
Apply Style Model(应用样式模型节点)
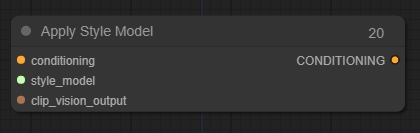
可用于为扩散模型提供进一步的视觉指导,特别是关于生成图像的风格
Conditioning (Combine) 调节(合并)节点
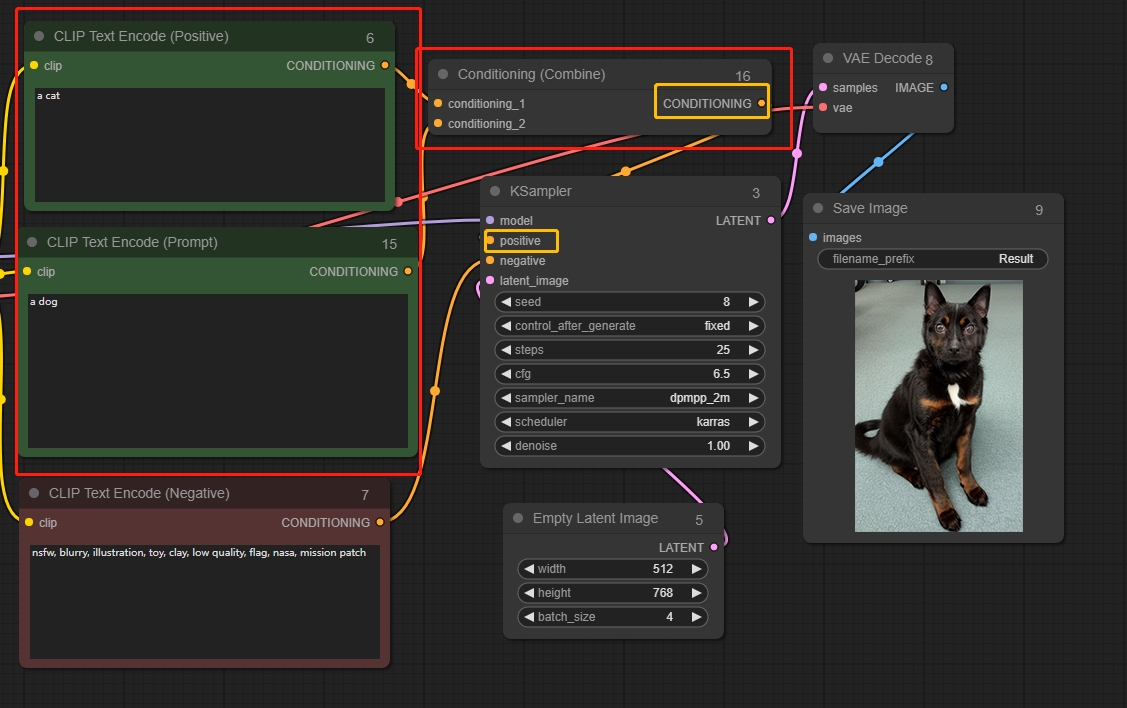
将两条信息进行混合
Conditioning (Set Area) 调节(设置区域)节点
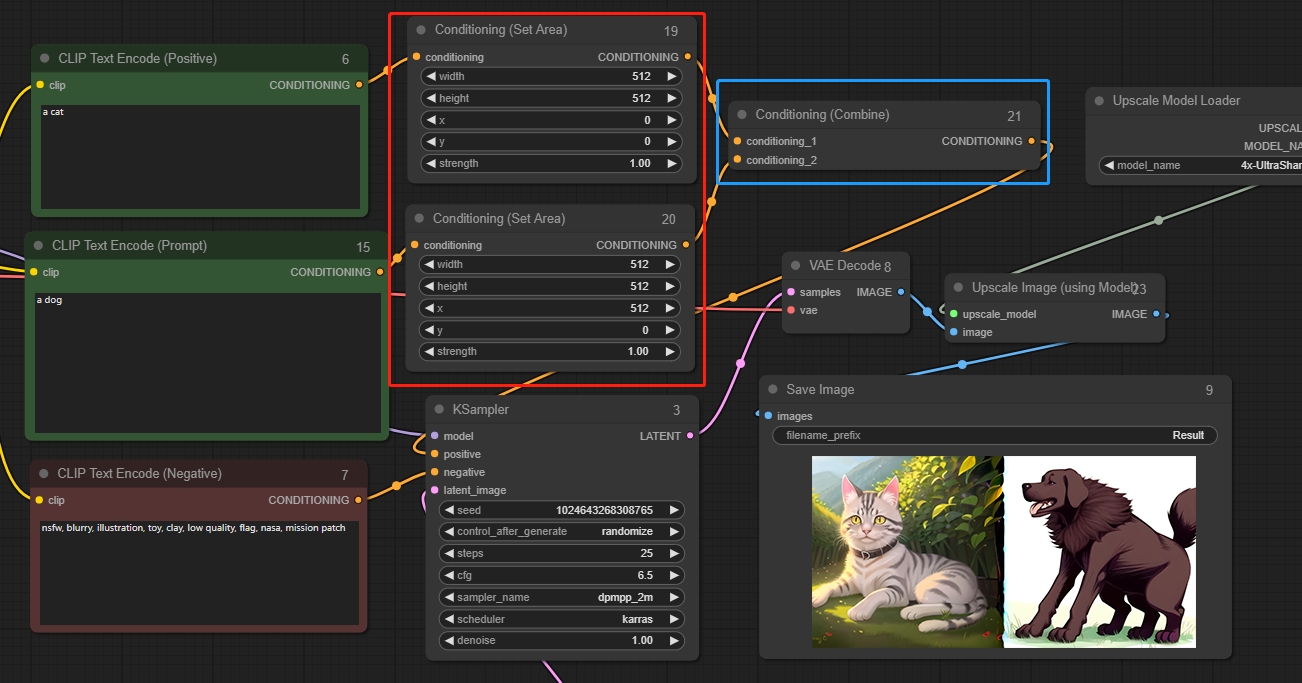
调节(设置区域)节点可用于将影响区域限制在图像的指定区域内。与Conditioning (Combine)节点一起使用,可以更好地控制最终图像的构成。
参数:
width:控制区域的宽度
height:控制区域的高度
x:控制区域原点的x坐标
y:控制区域原点的y坐标
strength:条件信息的强度
*坐标原点位于图片左上角
Conditioning (Set Mask) 调节(设置遮罩)节点
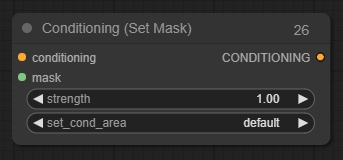
Conditioning (Set Mask)可用于将一个调节限制在指定的遮罩内。与Conditioning (Combine)节点一起使用,可以更好地控制最终图像的构成
Latent 潜空间
VAE Encde(for Inpainting)(VAE 编码节点(用于修复))
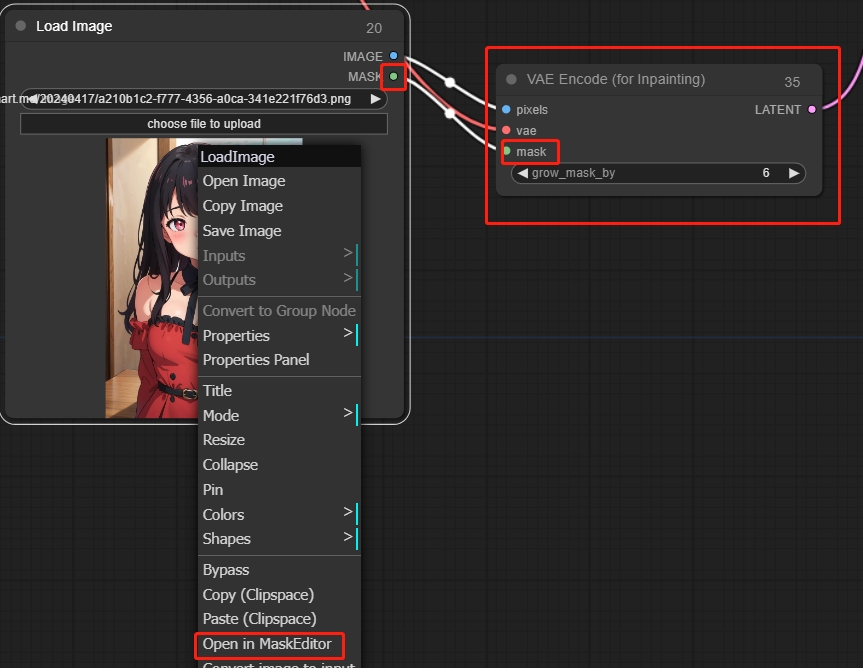
适用于局部重绘,右键单击,通过涂抹蒙版实现局部重绘
Set Latent Noise Mask(设置潜在噪声遮罩节点)
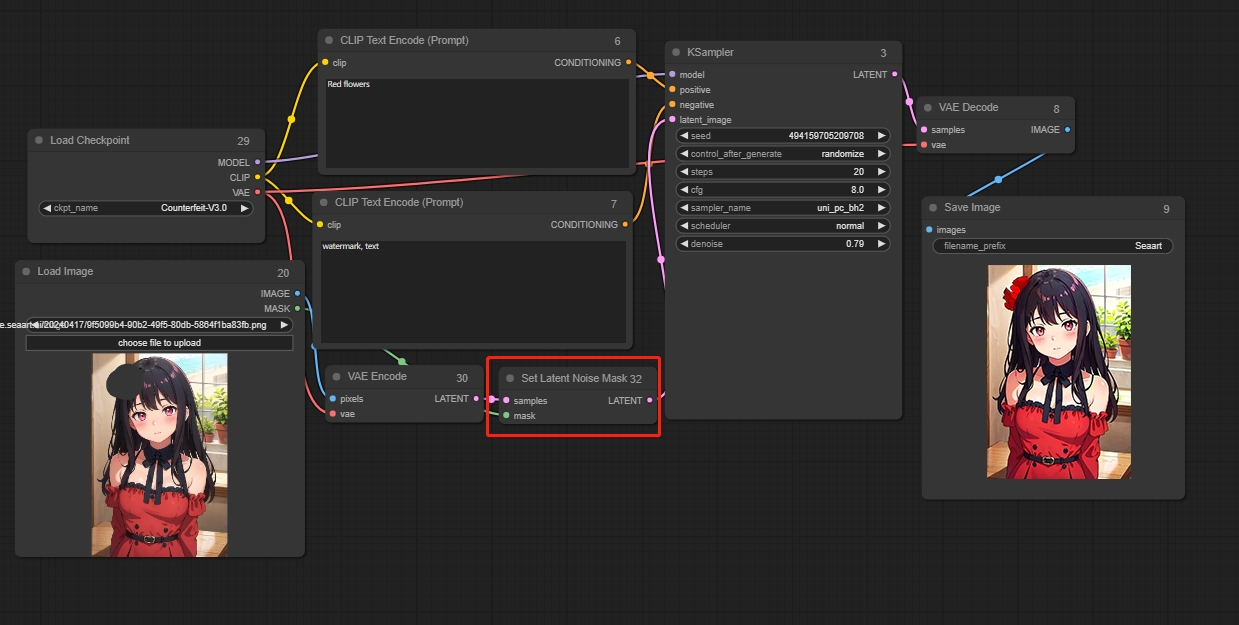
局部重绘的第二种方式,先将图片通过vae编码器变成潜空间能识别的内容,再在潜空间处将遮罩部分重新生成一次
相比VAE Encde(for Inpainting)方式,能更好的理解需要重新生成的内容,生成错误图片的概率更低,会参考图片进行重新绘制
Rotate Latent(旋转潜像节点)
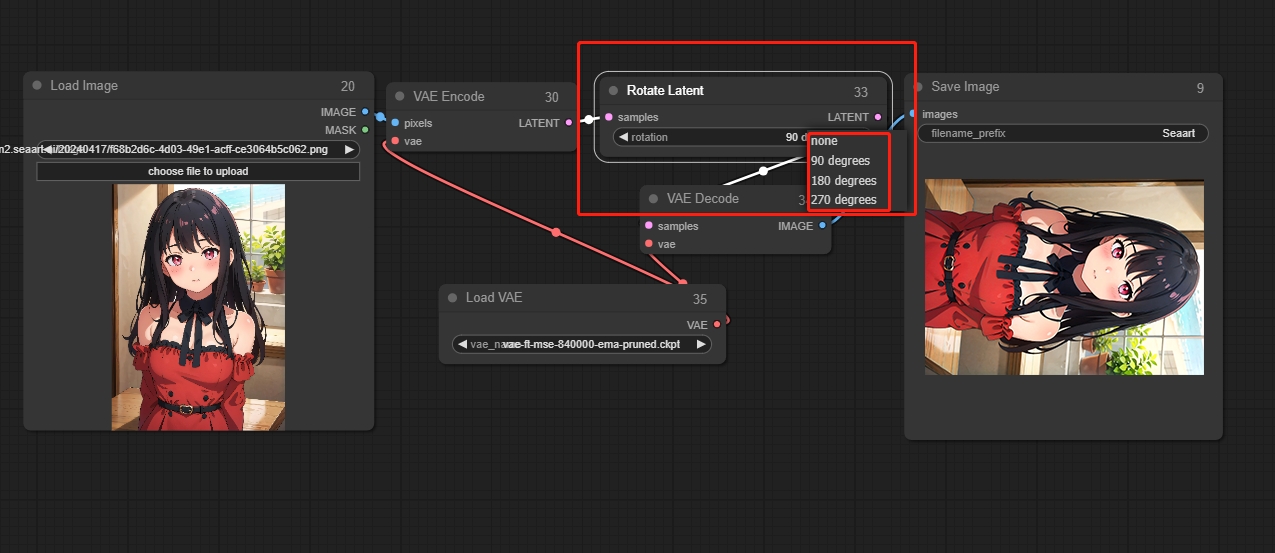
将图像顺时针旋转
Flip Latent(翻转潜像节点)
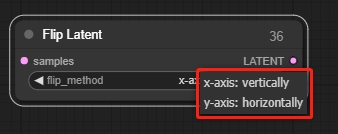
水平或垂直翻转图像
Crop Latent(裁剪潜像节点)
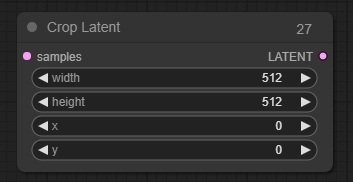
用于将潜在图像裁剪成新的形状
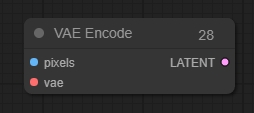
VAE Encode(VAE 编码节点)
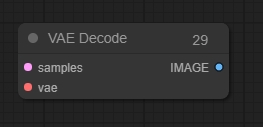
VAE Decode(VAE 解码节点)
Latent From Batch(批次中提取潜在图像)
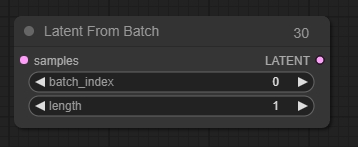
从批次中提取潜像图,Latent From Batch 节点可以用于从批次中选择一个潜像图或图像片段。这在工作流中需要隔离特定的潜像图或图像时非常有用
Repeat Latent Batch(重复潜在图像批次处理节点)
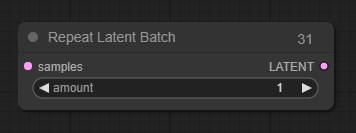
重复一批图像,可用于图像到图像的工作流程中创建一个图像的多个变体
参数:
amount: 重复次数
Rebatch Latents(重新批处理潜像节点)
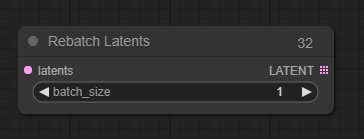
可以用于拆分或合并批量的潜在空间图像
Upscale Latent(放大潜在图像节点)
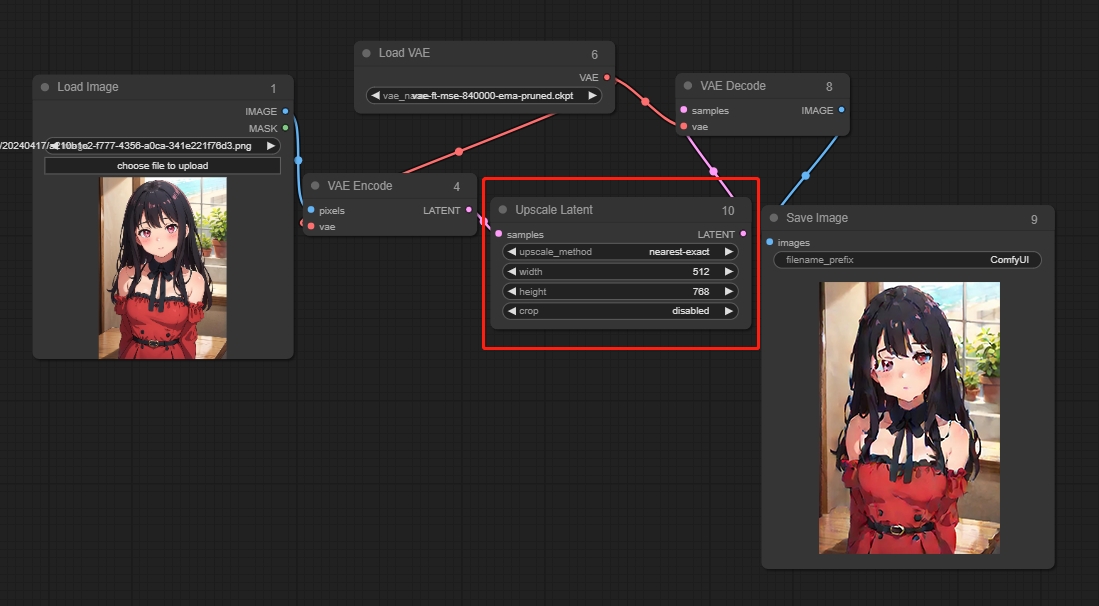
对潜空间图像进行分辨率调整,仅使用数学方式进行像素填充
参数:
upscale_method:表示像素填充的方法
width:调整后潜空间图像的宽度
height:调整后潜空间图像的高度
crop:表示是否对图像进行裁剪
*潜空间放大的图像,通过VAE解码后会出现毁坏的情况,可以使用KSampler采样器进行二次采样,从而修复图像
Latent Composite(潜在复合节点)
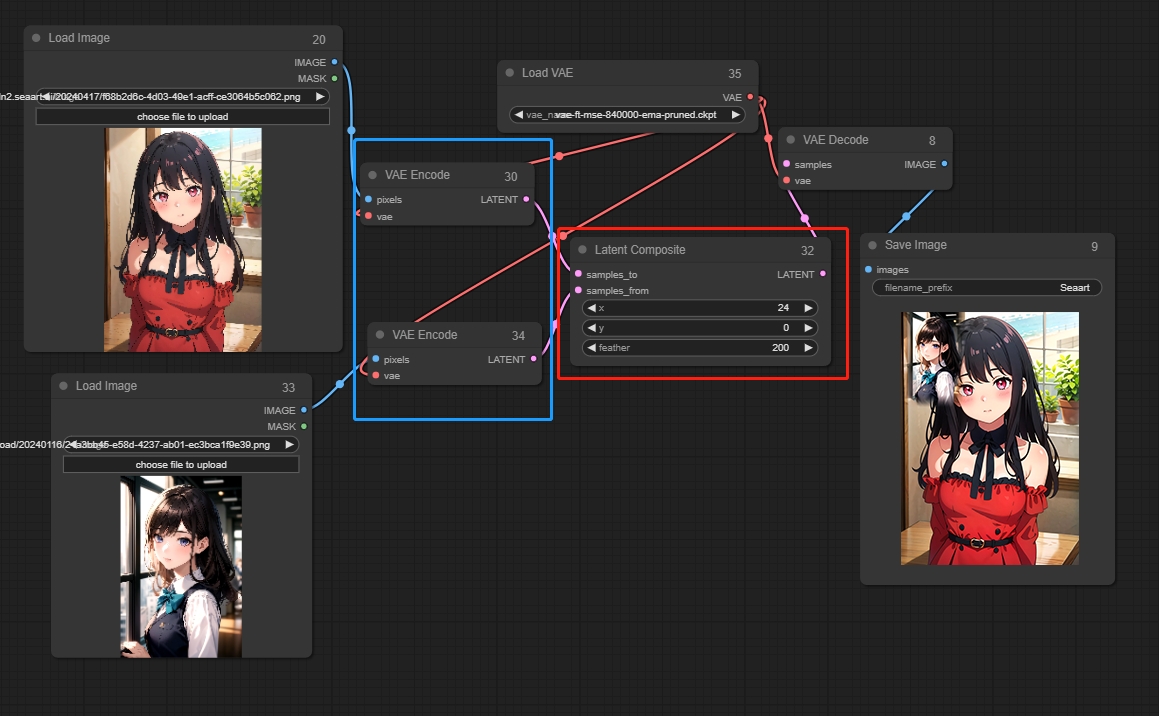
将一个图像叠加到另一个上
参数:
x:上层图层叠加位置的的x坐标
y:上层图层叠加位置的的y坐标
feather: 边缘的羽化程度
*图像需要经过编码(VAE Encode)进去潜空间
Latent Composite Masked(潜在复合遮罩节点)
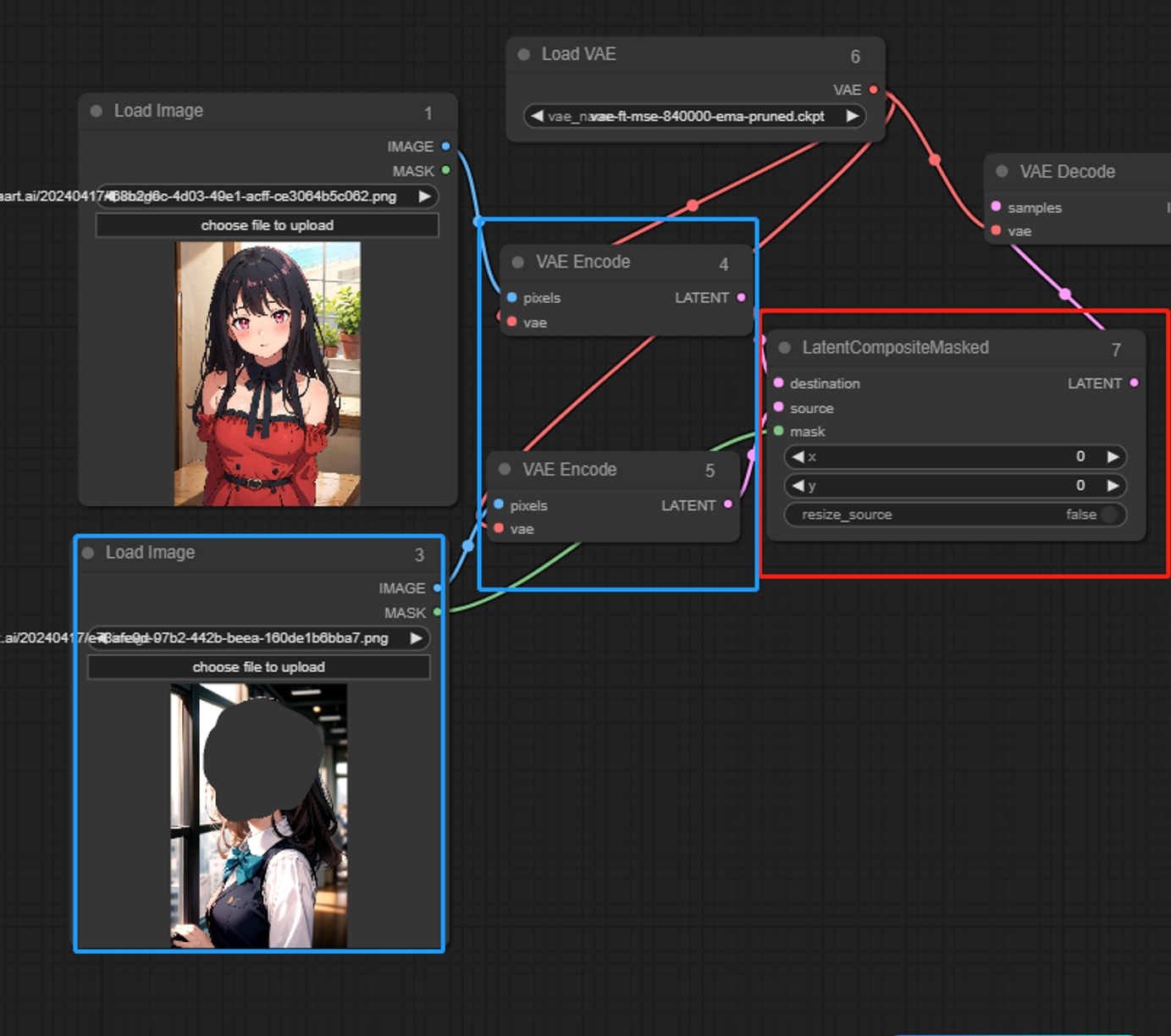
将一个带遮罩的图像叠加到另一个上,仅叠加遮罩部分
输入:
destination:底层潜空间图像
source:上层潜空间图像
参数:
x:表示叠加区域的x坐标
y:表示叠加区域的y坐标
resize_source:表示是否对蒙版区域进行分辨率调整
Empty Latent Image(空潜在图像节点)
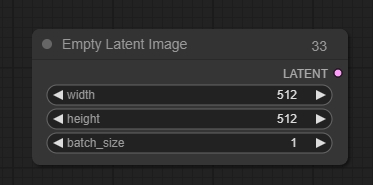
空潜在图像节点可用于创建一组新的空潜在图像。这些潜在图像随后可以在例如text2image工作流中通过使用采样节点对它们进行加噪和去噪来使用
Mask 遮罩
Load Image As Mask(加载图像作为遮罩节点)
Invert Mask(反转遮罩节点)
Solid Mask(实心遮罩节点)
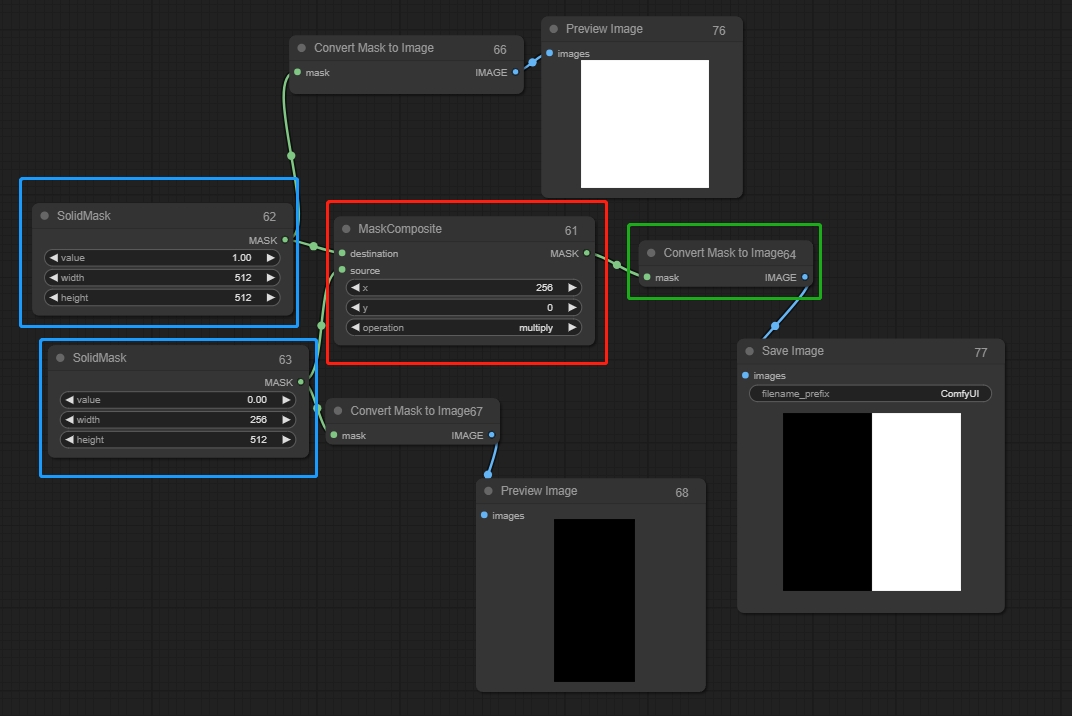
相当于生成图片的画布,可以与Mask Composite结合
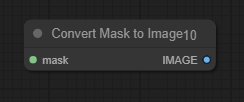
Convert Mask To Image(将遮罩转换为图像节点)
Convert Image To Mask(将图像转换为遮罩节点)
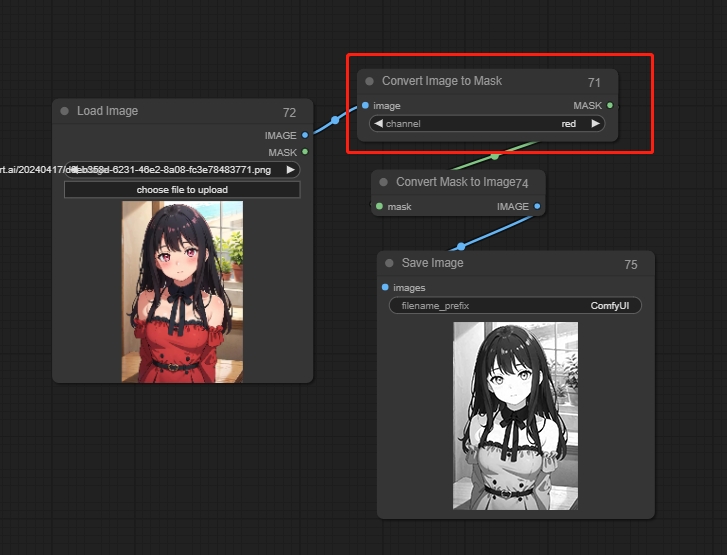
将遮罩转换为灰度图像
Feather Mask(羽化遮罩节点 )
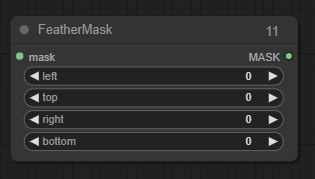
对遮罩进行羽化处理
Crop Mask(裁剪遮罩节点 )
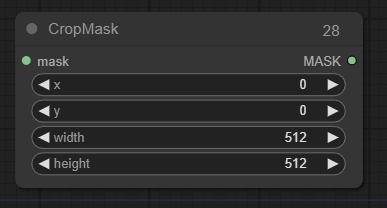
将遮罩裁剪为新的形状
Mask Composite(遮罩合成节点)
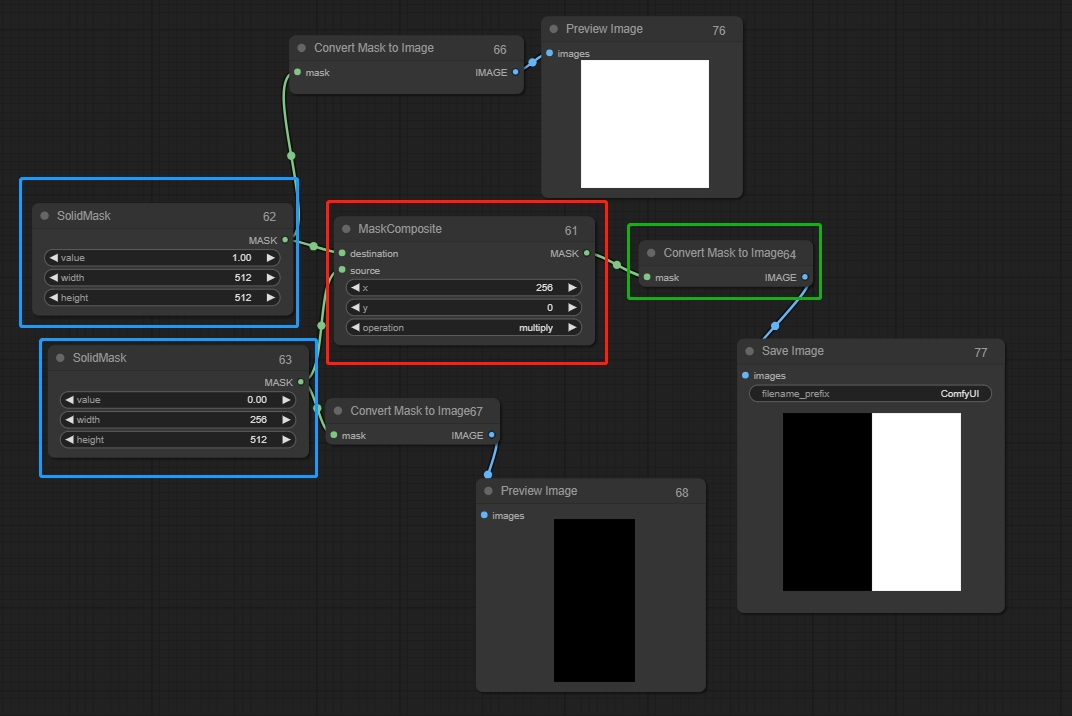
将一个遮罩粘贴到另一个遮罩中,连接Solid Mask,Value为0表示黑色,不会被绘制,Value为1表示白色,会被绘制,连接的两个Solid Mask中的Value需要不一样,否则蒙版不会生效
输入:
destination(1):要粘贴进去的遮罩,相当于最后生成图片的尺寸
source(0):要被粘贴的遮罩
参数:
X,Y:对source的位置进行调整
operation(混合方法): source为0时使用multiply,为1时使用add
Sampler 采样
KSampler(K采样器)
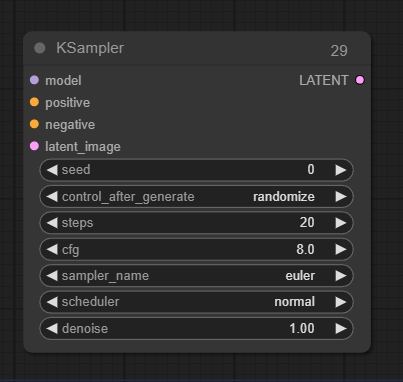
输入:
latent_image:将被去噪的潜在图像
输出:
LATENT:去噪后的潜在图像
KSampler Advanced(高级K采样器节点)
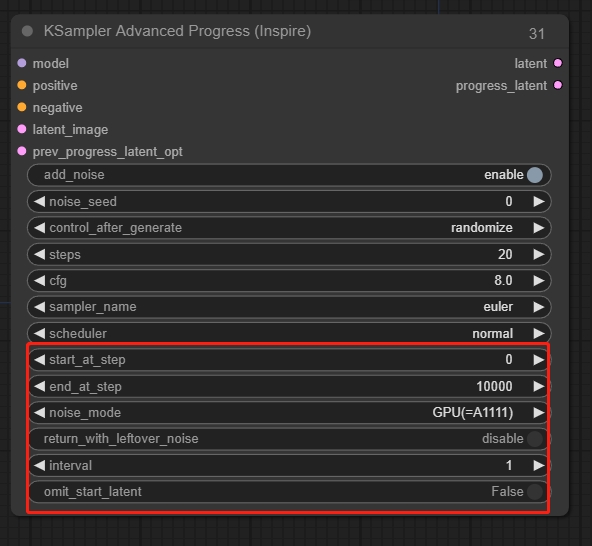
可以手动控制噪声
高级节点
Load Checkpoint With Config 【加载Checkpoint(带配置)】
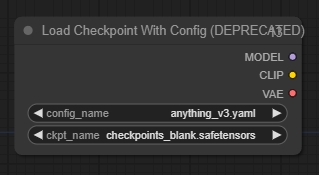
根据提供的配置文件加载扩散模型
其他节点(更新中...)
AIO Aux Preprocessor(Aux集成预处理器)
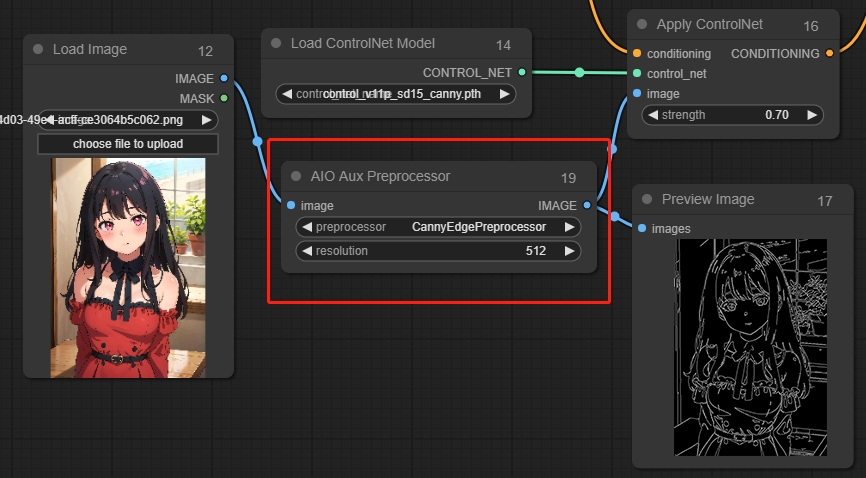
选择不同预处理器生成相应图像
Last updated