2-1 Texto a imagen
Aprende qué es texto a imagen y cómo usar el generador de IA de texto a imagen con instrucciones fáciles, paso a paso.
¿Alguna vez te has encontrado con problemas similares al usar SeaArt: el efecto de control no es ideal, o los resultados del dibujo no reflejan los prompts añadidos, entre otros? En esta guía, presentaremos de forma completa cómo dominar el funcionamiento de texto a imagen y captar la estrategia para redactar prompts eficientes.
1. ¿Qué es Texto a imagen?
En SeaArt AI, hay tres modos de dibujo: Texto a imagen, Imagen a imagen, y ControINet
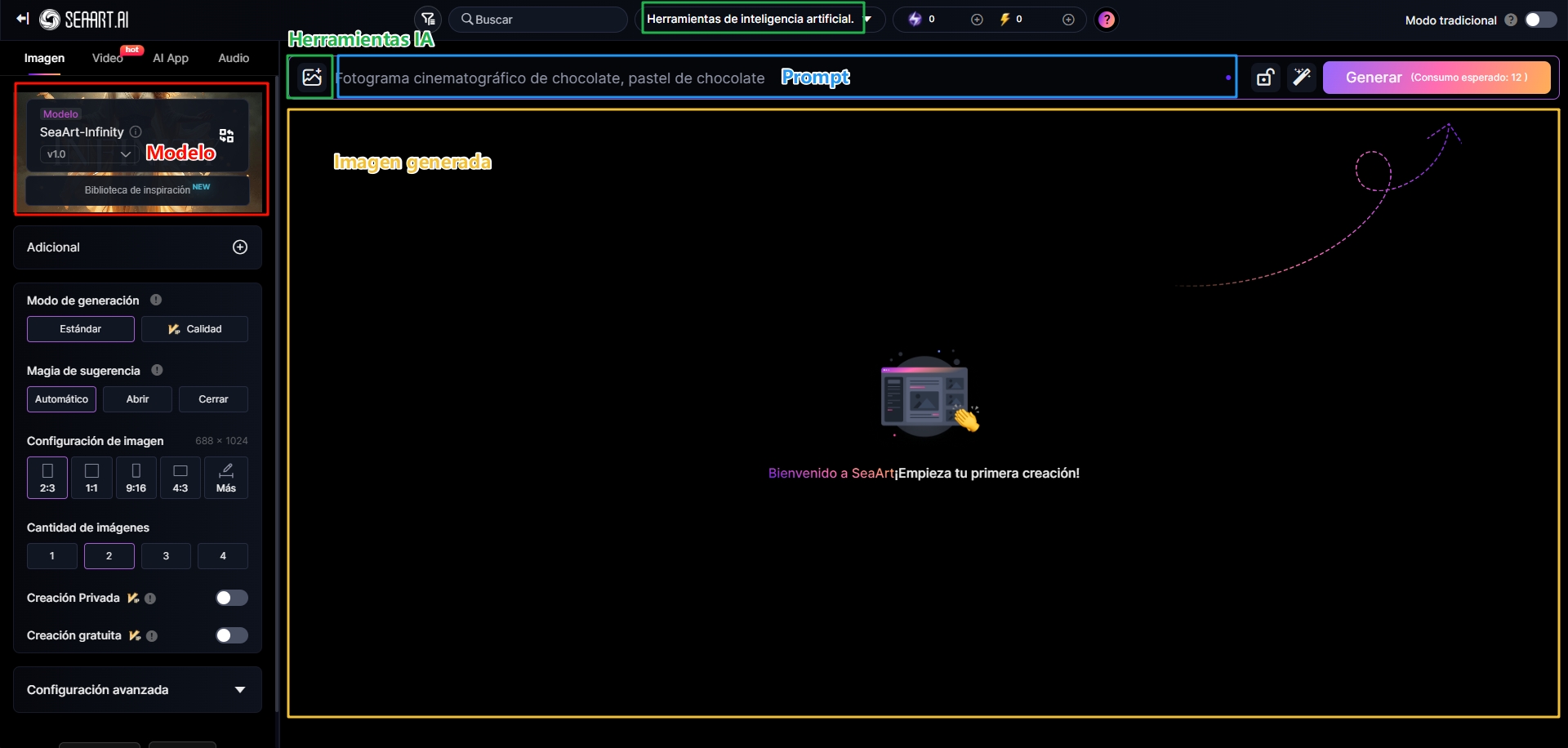
Los pasos básicos para dibujar son: seleccionar un modelo → ingresar prompts → ajustar parámetros → generar.
El modelo determina el estilo, los prompts definen el contenido de la imagen y los parámetros refinan las características preestablecidas de la imagen.
2. Redacción de prompts – Básico y avanzado
¿Qué es un prompt? ¿Cómo redactar un buen prompt?
Un prompt es una descripción textual que guía a la IA para generar contenido. Un buen prompt debe ser claro y específico, cubriendo aspectos clave como estilo, contenido y detalles. Ejemplo: “estilo anime japonés, chica, bajo un cerezo en flor, sonriente, día soleado.” Recomendamos consultar ejemplos de la comunidad y adquirir experiencia gradualmente.
Sintaxis básica y estructura del prompt
Usa comas para separar palabras clave; el orden afecta los resultados.
Usa paréntesis o pesos para enfatizar palabras clave, p. ej., (gato:1.2).
Soporta múltiples idiomas, pero se prefiere inglés o el idioma que recomiende la plataforma.
Usa prompts negativos para excluir elementos no deseados.
Cómo establecer pesos en los prompts (explicación detallada)
El peso enfatiza la importancia de las palabras clave. El formato común: (palabra:1.5) significa peso = 1.5 (mayor influencia).
Múltiples palabras pueden tener pesos individuales, ej.: (gato:1.2), (perro:0.8).
El soporte varía entre modelos; consulta documentación o consejos comunitarios.
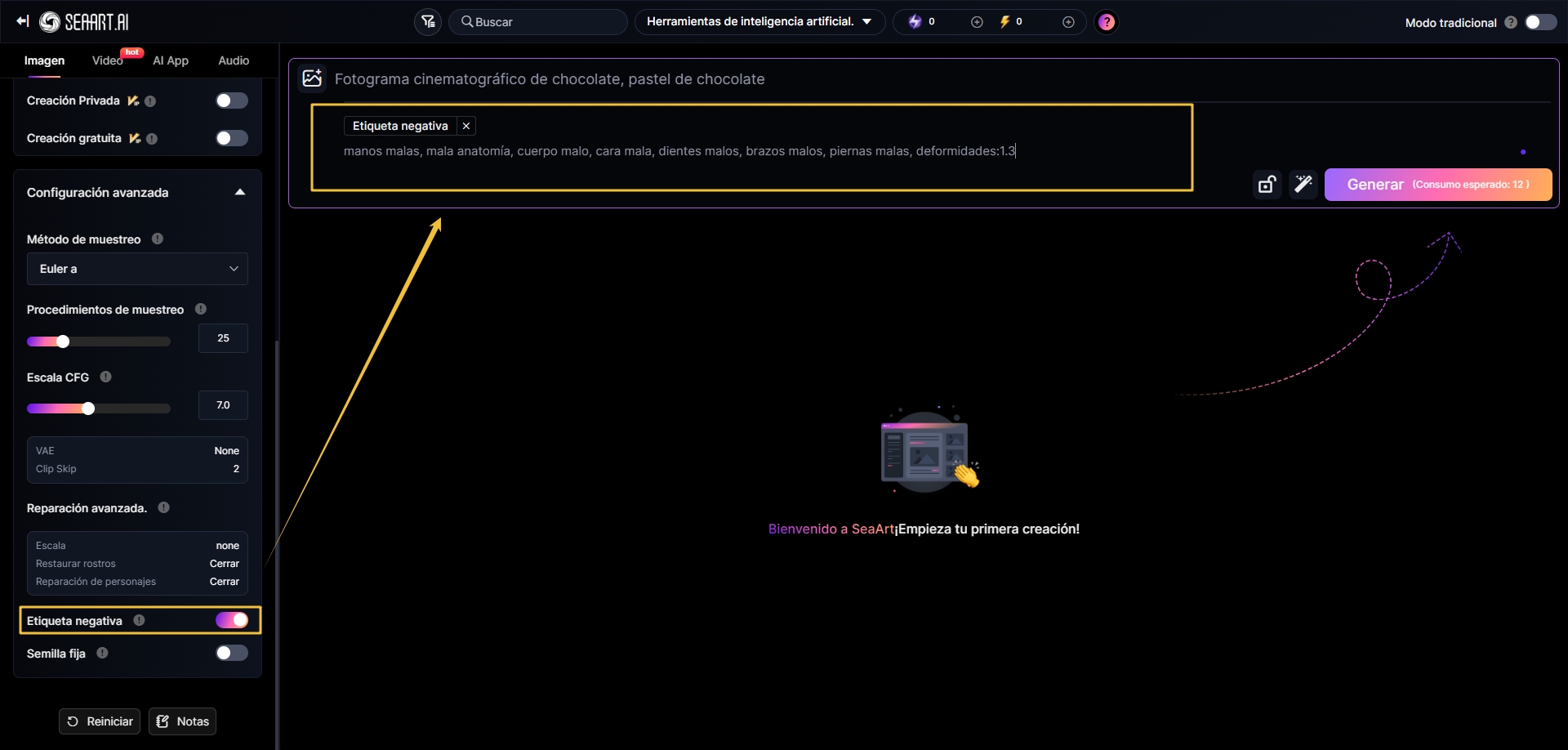
Cómo usar prompts negativos
En el campo de prompt negativo, introduce elementos no deseados como: “borroso, baja calidad, marca de agua.” Usa pesos para reforzar las exclusiones, ej: (múltiples personas: 1.5) para controlar retratos individuales.
Los prompts negativos son especialmente útiles cuando algunos modelos no comprenden bien detalles específicos (por ejemplo, la estructura de las manos), ya que ayudan a evitarlos y mejorar la calidad de la imagen.
Por ejemplo, incluye: (manos malas, mala anatomía, cuerpo malo, cara mala, dientes malos, brazos malos, piernas malas, deformidades:1.3)
Prompts de entrada: lenguaje natural o formato de frase
Lenguaje natural: Una chica con cabello negro bailando
Formato de frase: Una chica, cabello negro, bailando
La función de los prompts es guiar al modelo, no ser un requisito estricto. Incluso con una frase casual, el modelo puede crear una imagen para ti, y el resultado puede ser incluso bastante bueno.

*Los prompts ricos permiten un mejor control del efecto final. En el proceso de ajuste fino posterior, se pueden modificar rápidamente palabras clave específicas y verificar su impacto en el resultado del dibujo.
Fórmula universal del prompt
Un prompt eficaz es como asignar una tarea al generador de arte con IA. Si la instrucción es vaga, como solo “diseña una imagen” sin especificar elementos y propósito, el resultado suele ser impredecible. Por eso, proporcionar instrucciones detalladas y específicas puede mejorar en gran medida la calidad y relevancia del resultado.
Por ejemplo, si el prompt simplemente es “una niña”, no menciona la vestimenta de la niña, la escena, el ángulo de la cámara, etc., y la IA solo puede basarse en su experiencia de entrenamiento. Gracias a las capacidades del modelo, los resultados aún pueden ser bastante buenos. Sin embargo, si tienes requisitos específicos sobre el contenido de la pantalla, esa eficiencia es muy baja.

Cuando añade otras palabras descriptivas, la imagen se volverá mucho más estable.

Una fórmula ideal de prompt incluye elementos como contenido principal, fondo ambiental, composición, ajustes de imagen y estilo de referencia, cada uno influyendo en el resultado de la generación gráfica.
*Esta fórmula es una referencia, no una regla estricta para cada creación de prompt. Primero, determina el impacto del contenido principal y luego optimiza detalles según tus necesidades.

Contenido principal: describe el sujeto principal como personas, animales, su vestimenta, expresiones, pelaje, acciones o materiales. Crear varios sujetos juntos puede presentar problemas; se recomienda generarlos por separado y luego integrarlos usando ControlNet.
Entorno ambiental: define la escena y elementos auxiliares como color del cielo, entorno, iluminación y tonos de color, mejorando la atmósfera y destacando el tema.
Composición de la toma: ajusta el ángulo y la perspectiva de la cámara, como profundidad de campo o disposición de objetos, para aumentar el impacto visual.
Ajustes de imagen: incluyen términos para mejorar la expresividad visual, como riqueza de detalles, calidad fotográfica y efecto cinematográfico. La resolución y el nivel de detalle se determinan principalmente por el tamaño, pudiendo mejorarse con técnicas de posprocesamiento como Upscale.
Estilo de referencia: describe el estilo artístico deseado y la ambientación, mencionando nombre de artista, técnica, época o paleta de colores. Sin embargo, el estilo depende mayormente del modelo; si el modelo no ha sido entrenado en ciertos estilos, puede no comprenderlos. Para requisitos de estilo específicos, usar un modelo entrenado en ese estilo puede dar mejores resultados que solo depender de prompts.
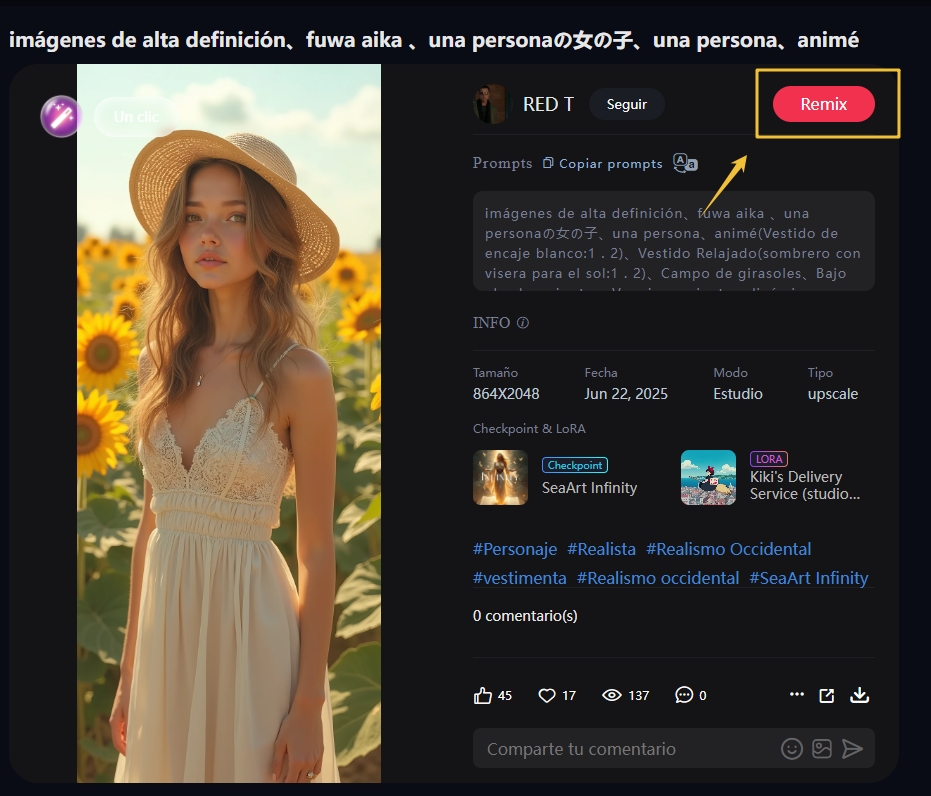
Remix: Si encuentras que redactar prompts es demasiado complejo, puedes buscar inspiración en imágenes generadas por IA en la página principal y reutilizar parámetros y prompts existentes con un clic para simplificar el proceso.

Prompts enfatizados
Enfatizar prompts se basa en paréntesis y valores numéricos para controlar el peso de partes específicas del prompt. Cuanto mayor sea el valor, más atención presta el modelo a esa parte, enfocándose en representarla durante el proceso. Como resultado, la imagen final reflejará más esa información. Por el contrario, menos atención resultará en menos presencia de ese contenido en la imagen.
Hay dos métodos:
1️⃣ Aumentar peso mediante paréntesis.
2️⃣ Ingresar valores numéricos directamente (más común).
Existen tres tipos de paréntesis para controlar el peso de las palabras indicadoras:
Paréntesis redondos ( ): Cada capa aumenta el peso original en 1.1 veces.
Paréntesis cuadrados [ ]: Cada capa disminuye el peso original 0.9 veces.
Además, los paréntesis admiten múltiples capas de apilamiento, en las que cada capa representa un peso multiplicado por un factor fijo.
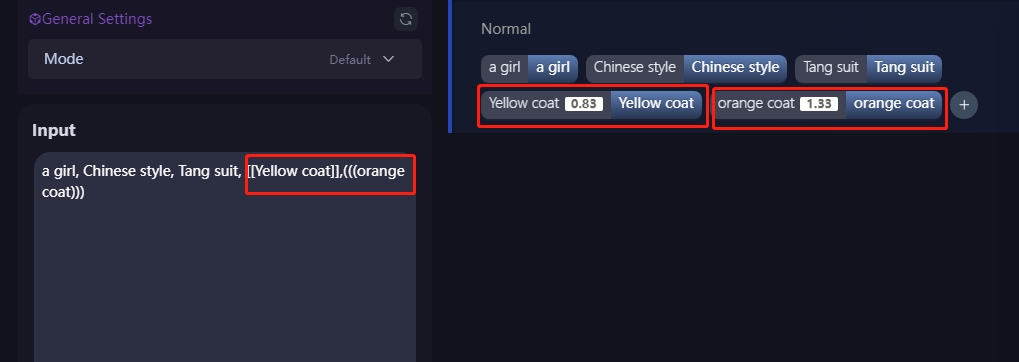
Por ejemplo, por defecto, la ropa de la niña será una combinación de amarillo y naranja. Sin embargo, cuando se utiliza “(((abrigo naranja)))”, con el paréntesis indicando un aumento del énfasis, se realza la representación del modelo del abrigo naranja, lo que hace que aparezca más naranja en el abrigo en la imagen final.

En cambio, cuando se utiliza "[[abrigo naranja]]", con los corchetes indicando una disminución del énfasis, los elementos naranjas disminuyen. El modelo dará prioridad a las palabras clave restantes "((abrigo amarillo))", con lo que el abrigo aparecerá más amarillo en la imagen final.

Introduzca directamente valores numéricos para controlar el peso.
Por ejemplo, por defecto, el pelo se presenta en colores verde y rojo. Si establecemos el peso después de "(pelo verde)" en 0.9, significa que el peso de la parte de pelo verde se reduce a 0.9 veces su valor original. Del mismo modo, si queremos aumentar el peso del pelo verde, podemos simplemente introducir 1.1 después.

*Aunque el énfasis en el peso de las palabras clave puede variar de 0.1 a 100, teniendo en cuenta las posibles desviaciones del efecto causadas por valores de peso extremos, se recomienda mantener el peso entre 0.5 y 1.5 para obtener resultados de imagen óptimos.
Para conocer los ajustes específicos de los parámetros, haz clic aquí para ver los detalles.
✨4-Parámetros