Conversión de Imágenes
¡Domina la conversión de imágenes con ComfyUI! Esta guía mejora el proceso de Imagen a Imagen con control preciso, referencia facial y escalado en alta definición.

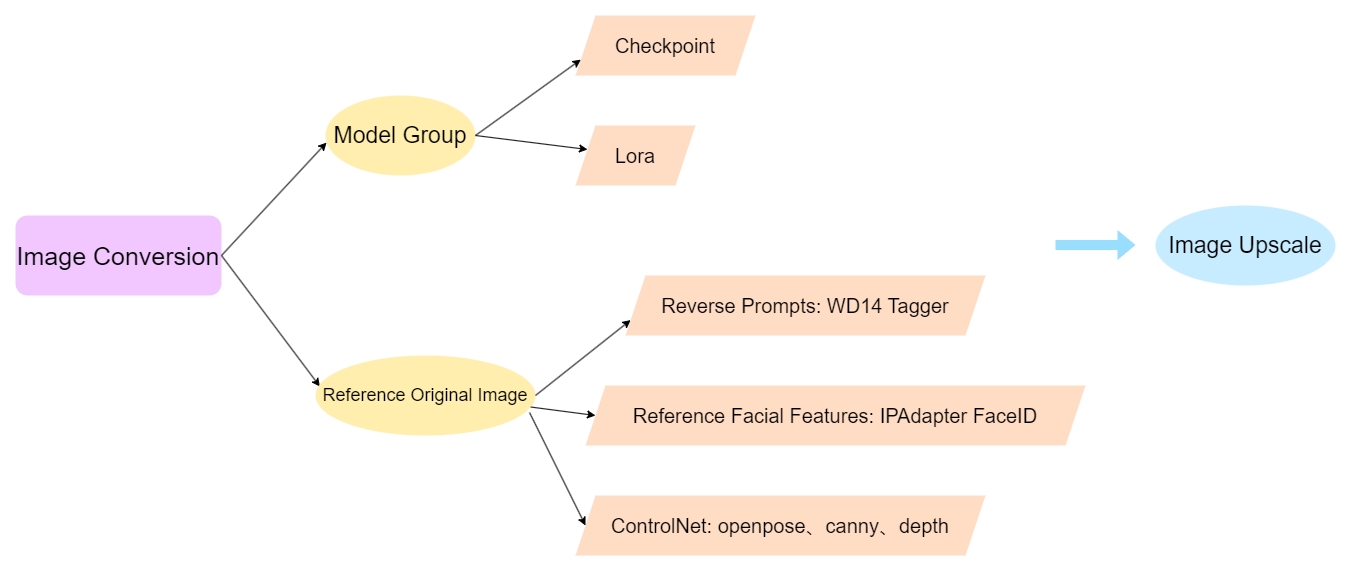
Proceso de pensamiento:
La conversión de imágenes en ComfyUI es similar a Img2Img en webui, donde subes una imagen original y su estilo se modifica mediante el modelo. Sin embargo, para aumentar la precisión de la conversión, podemos añadir algunos pasos nuevos:
I. Añade un nodo de aumento de modelo para controlar el tamaño de la imagen original. II. Incrementa la similitud con la imagen original:
a. Usa ipadapter faceid para referenciar rasgos faciales.
b. Ingresa los prompts originales mediante ingeniería inversa.
c. Añade ControlNet (openpose, canny, depth).
III. Escala la imagen final a alta definición.
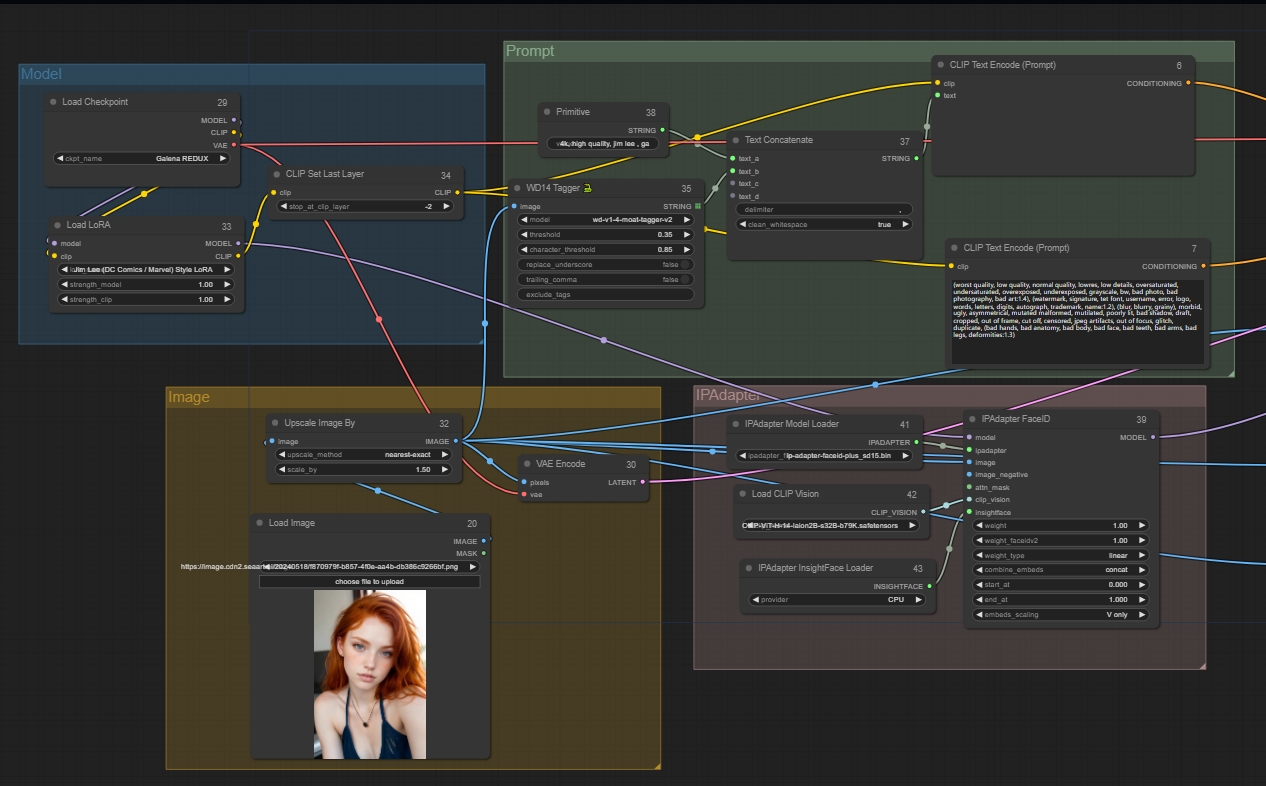
Paso 1: Construir el grupo de modelos
Puedes empezar basándote en la plantilla Imagen a imagen. Primero, añade selectivamente un nodo "Upscale Image By" detrás de la imagen original para controlar su tamaño. Puedes agregar Lora según tus necesidades o no añadirlo. Añade un nodo "CLIP Set Last Layer" según necesites, este nodo puede omitirse. Este nodo permite saltar capas y finalmente conectar los nodos correspondientes.
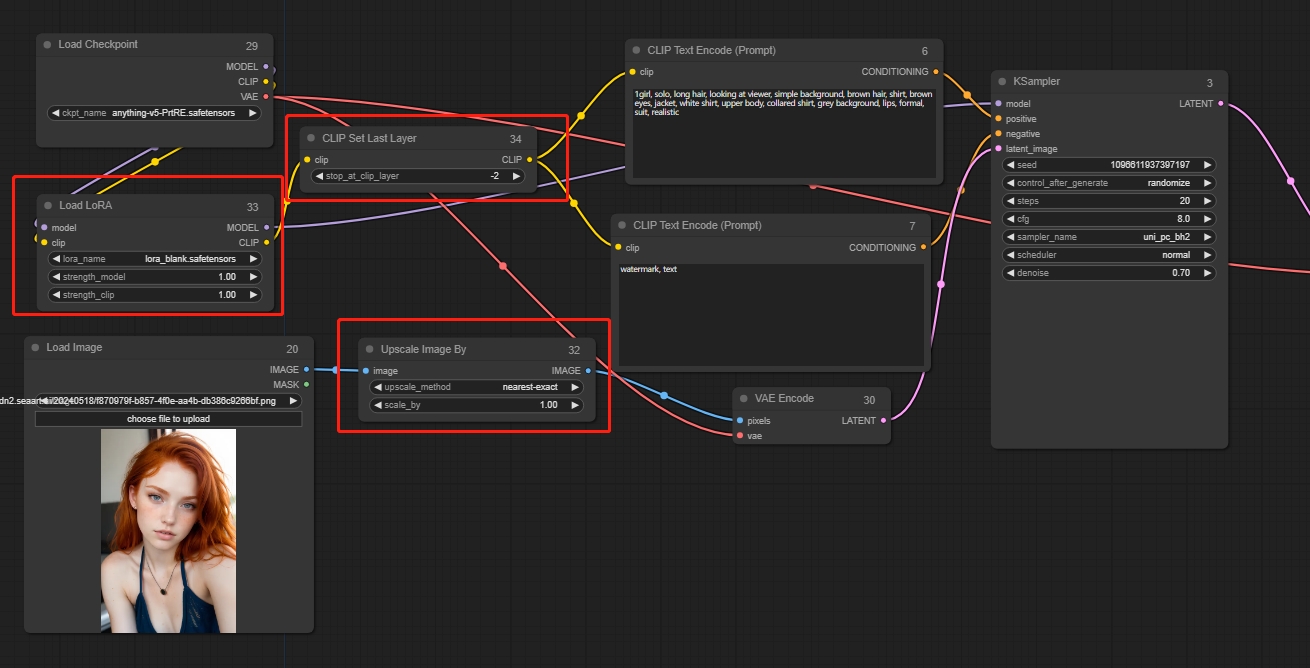
Añadir nodos:
Upscale Image By
CLIP Set Last Layer
Paso 2: Referenciar la imagen original
(Ingeniería inversa de prompts + Ipadapter + ControlNet)
Ingeniería inversa de prompts: nodo WD14 Tagger
Haz doble clic para buscar y añadir el nodo WD14 Tagger.
Conecta el nodo de imagen.
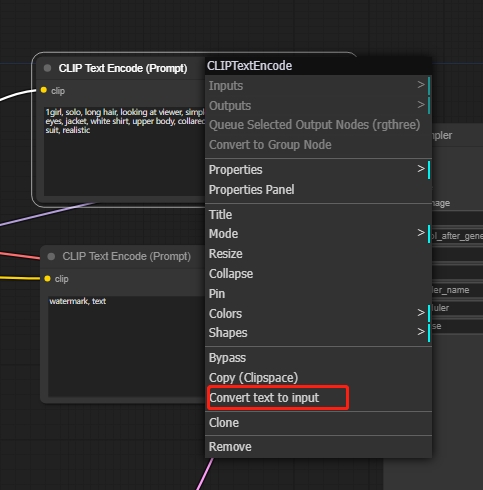
Haz clic derecho en el nodo de prompts positivos y selecciona "Convertir texto a entrada" para conectar WD14 Tagger al nodo de prompts positivos.
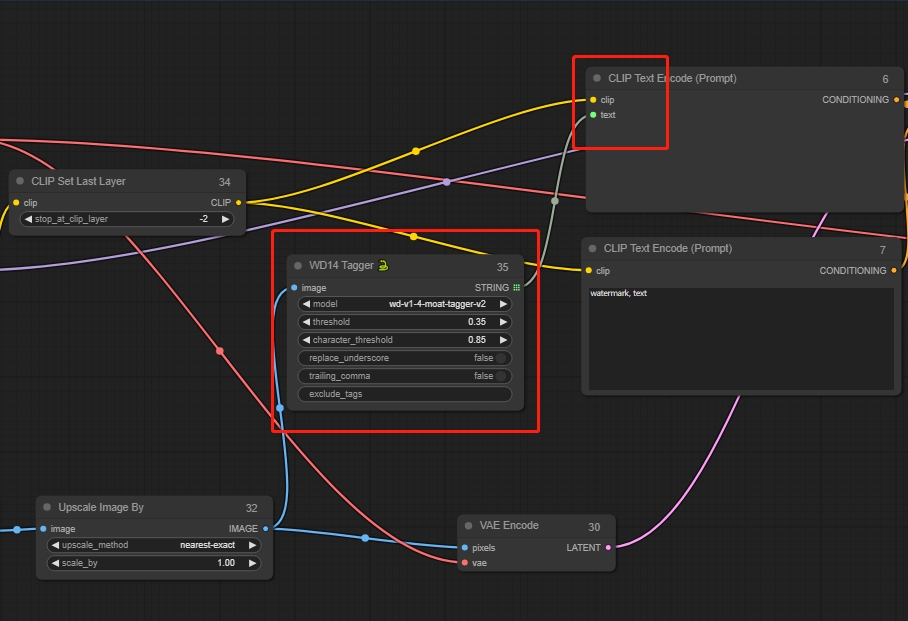
Esto solo incluye los prompts extraídos de la imagen. Si quieres añadir otros prompts, crea un nuevo nodo de Texto Concatenado, que puede conectar múltiples segmentos de prompts.
Luego crea un nodo Primario. Este nodo puede conectarse a cualquier otro para ser un atributo relacionado.
Ingresa prompts adicionales en el nodo Primario, como palabras disparadoras de Lora, palabras de calidad, etc.
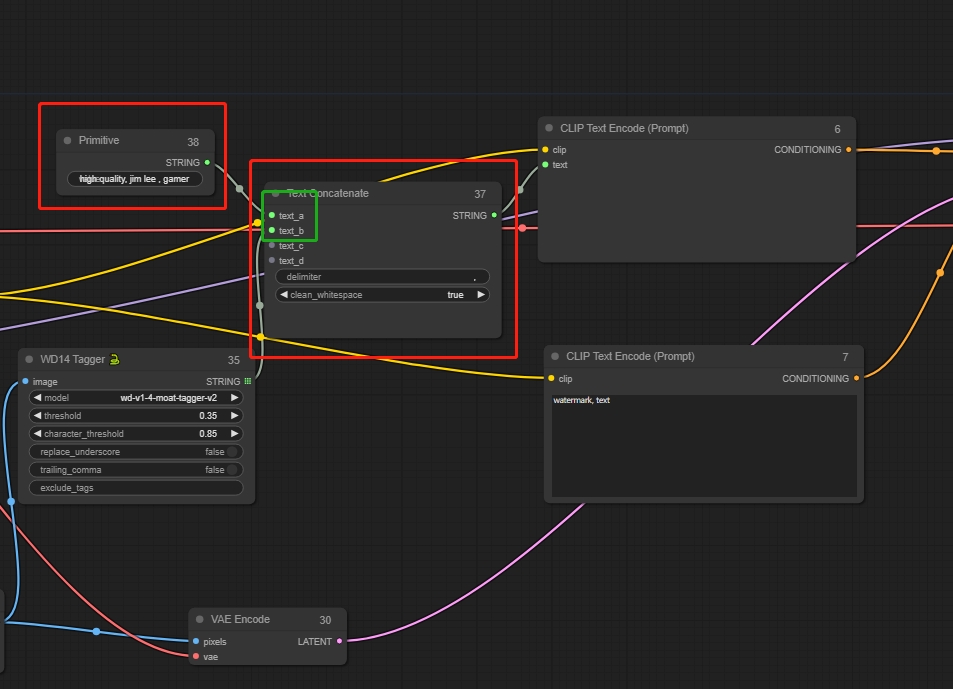
Así, los prompts incluyen tanto los extraídos como los que tú ingreses.
A continuación, configura el IPadapter FaceID para hacer referencia a los rasgos faciales:
Haga doble clic para buscar IPadapter FaceID y haga coincidir los nodos de entrada en consecuencia.
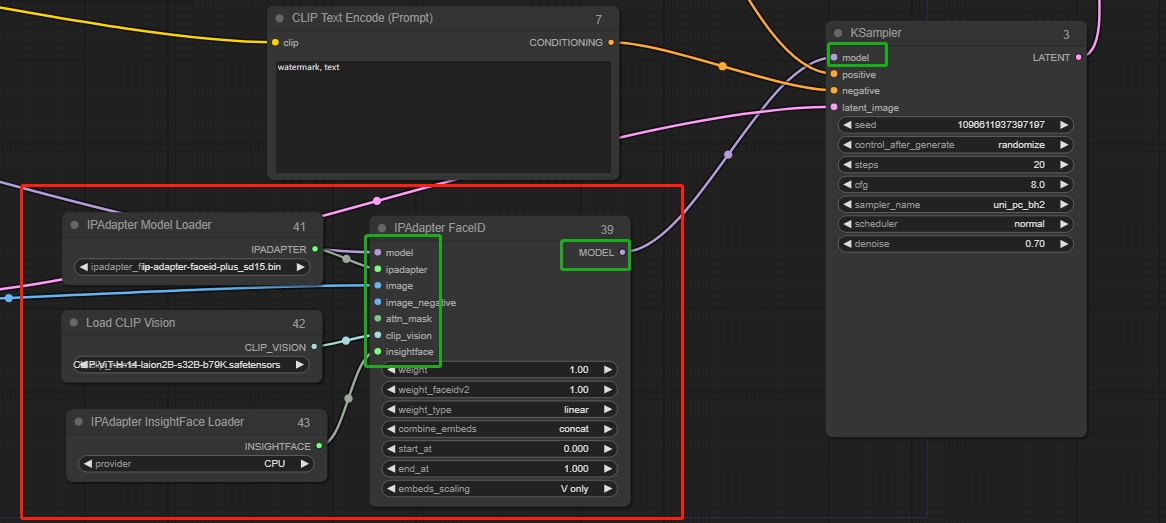
Después de sacar el nodo, crea nuevos nodos:
ipadapter → IPAdapter Model Loader
clip_vision → Load CLIP Vision
insightface → IPAdapter InsightFace Loader
Conecta la salida al sampler.
Añadir nodos:
IPadapter FaceID
IPAdapter Model Loader
Load CLIP Vision
IPAdapter InsightFace Loader
Configura ControlNet
Se recomienda usar el nodo CR Multi-ControlNet Stack, que permite añadir múltiples ControlNets. Añade los preprocesadores correspondientes. Recomendamos usar OpenPose, Canny y Depth como ControlNets, que puedes añadir o eliminar según las necesidades visuales finales. Luego añade un nodo de aplicación ControlNet en la salida: CR Apply Multi-ControlNet. Se recomienda fijar la resolución en el preprocesador a 1024.
*Por último, recuerda encender los interruptores de la ControlNet que vayas a utilizar.
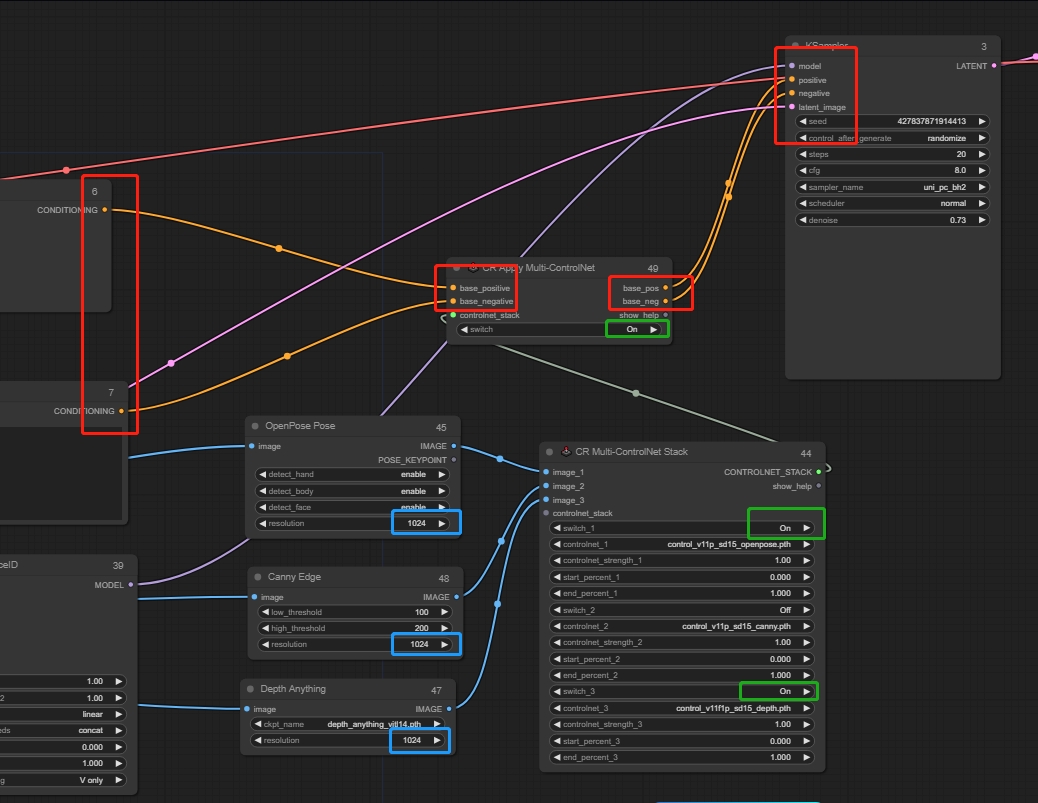
Entrada: conectada a los nodos de prompts positivos y negativos.
Salida: conectada al sampler.
Nodos a añadir:
CR Multi-ControlNet Stack
CR Apply Multi-ControlNet
Paso 3: Restauración en alta definición
Tras configurar el grupo de modelos y referenciar la imagen original, puedes añadir un paso de restauración en alta definición al resultado final:
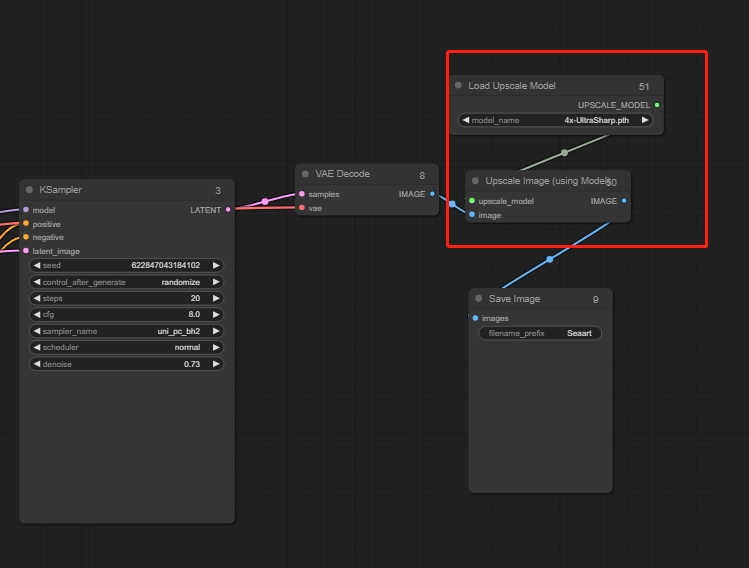
Añadir nodos: Upscale Image (usando modelo)
Después de montar los nodos, puedes organizarlos en un grupo para facilitar la visualización.
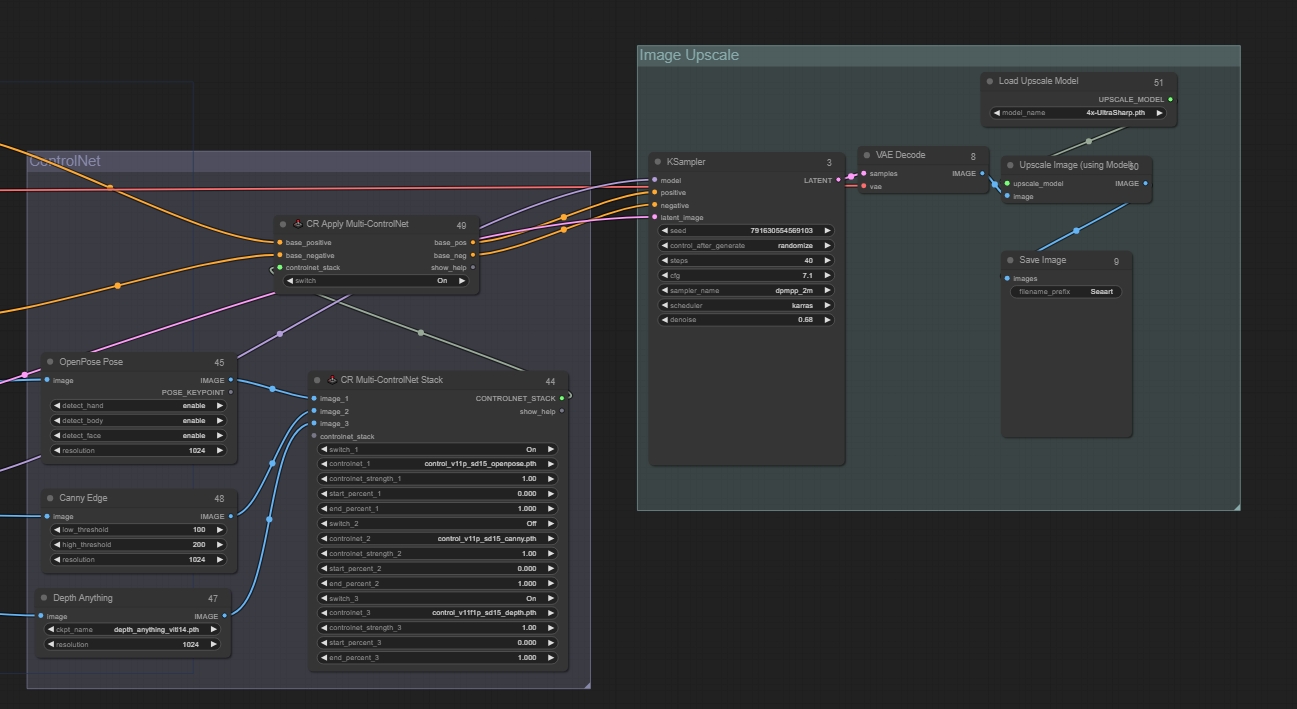
Finalmente, ajusta los parámetros relevantes basados en la imagen de salida, como ckpt, pesos de Lora, palabras de prompt, sampler, escala de redibujo, etc.
Parámetros clave para esta conversión:
CLIP_layer: -2
Upscale Image By: 1.5
steps: 40
sampler_name: dpmpp_2m
scheduler: karras
denoise: 0.7
Nota: Si eliges el modelo SDXL, también necesitarás el Lora correspondiente de SDXL y ajustar el ControlNet a SDXL; de lo contrario, la salida de la imagen fallará.
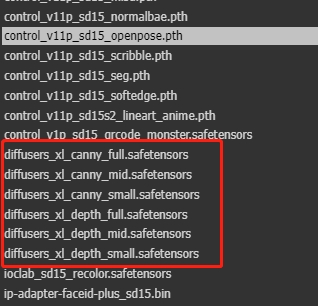
Lo anterior es un flujo de trabajo completo para la conversión de imágenes. A partir de esto, también puedes añadir VAE o FreeU_V2 para ajustar la imagen final:
FreeU_V2: controla principalmente el color y extrae ciertos contenidos para su optimización.
Load VAE: ajusta con precisión el color y los detalles de la imagen.

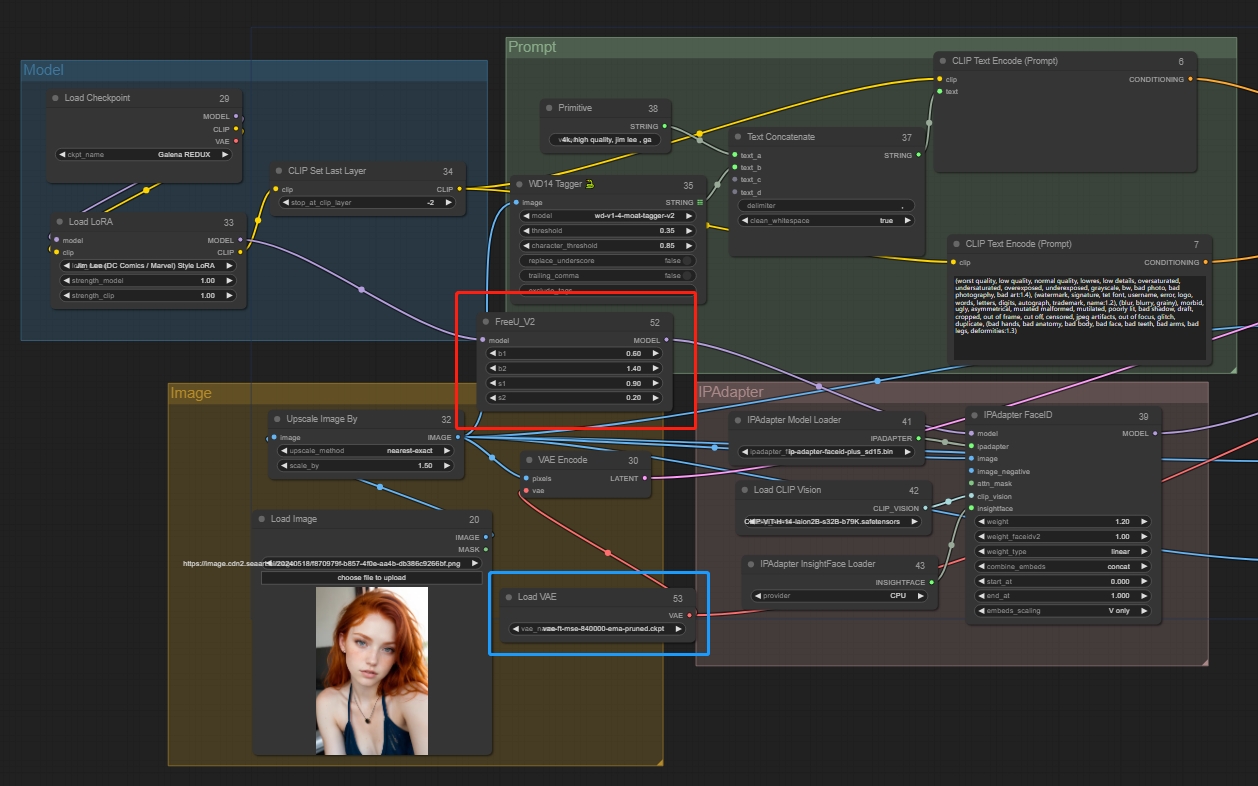
Mediante este flujo de trabajo, puede conseguir conversiones a diferentes estilos.