4-4 Configuración avanzada
¡Ajusta finamente tu arte con IA en SeaArt! Domina los prompts negativos, VAEs, sampling, escala CFG, seed y clip skip para un control preciso.
Proceso de creación: Seleccionar modelo – Ingresar prompts – Ajustar parámetros – Generar
Prompts negativos
Generalmente, es difícil para el modelo entender negaciones en los prompts, como palabras tipo “no,” “sin,” “excepto,” o “excepto.” Por eso, necesitamos incluir los efectos no deseados en los Prompts Negativos. Además de añadir elementos que no queremos en la imagen, podemos incluir palabras como “baja calidad,” “pocos detalles,” “feo,” “deformado,” etc. Esto ayuda a mejorar la calidad final de la imagen. Por lo general, al generar imágenes, SeaArt incluye automáticamente

(peor calidad, baja calidad, calidad normal, lowres, pocos detalles, sobresaturado, infrasaturado, sobreexpuesto, subexpuesto, escala de grises, bw, mala foto, mala fotografía, mal arte:1.4), (marca de agua, firma, fuente tet, nombre de usuario, error, logotipo, palabras, letras, dígitos, autógrafo, marca comercial, nombre:1. 2), (borrosa, desenfocada, granulada), mórbida, fea, asimétrica, mutada malformada, mutilada, mal iluminada, mala sombra, borrador, recortada, fuera de cuadro, recortada, censurada, artefactos jpeg, desenfocada, fallo, duplicada, (malas manos, mala anatomía, mal cuerpo, mala cara, malos dientes, malos brazos, malas piernas, deformidades:1.3)
VAE
El VAE puede considerarse un tipo de “filtro” que mejora la calidad de generación de imágenes y optimiza los efectos visuales mediante algoritmos. También puede hacer ajustes ligeros en las formas de las imágenes. Si notas problemas de color en las imágenes, puedes probar cambiar a otro VAE.
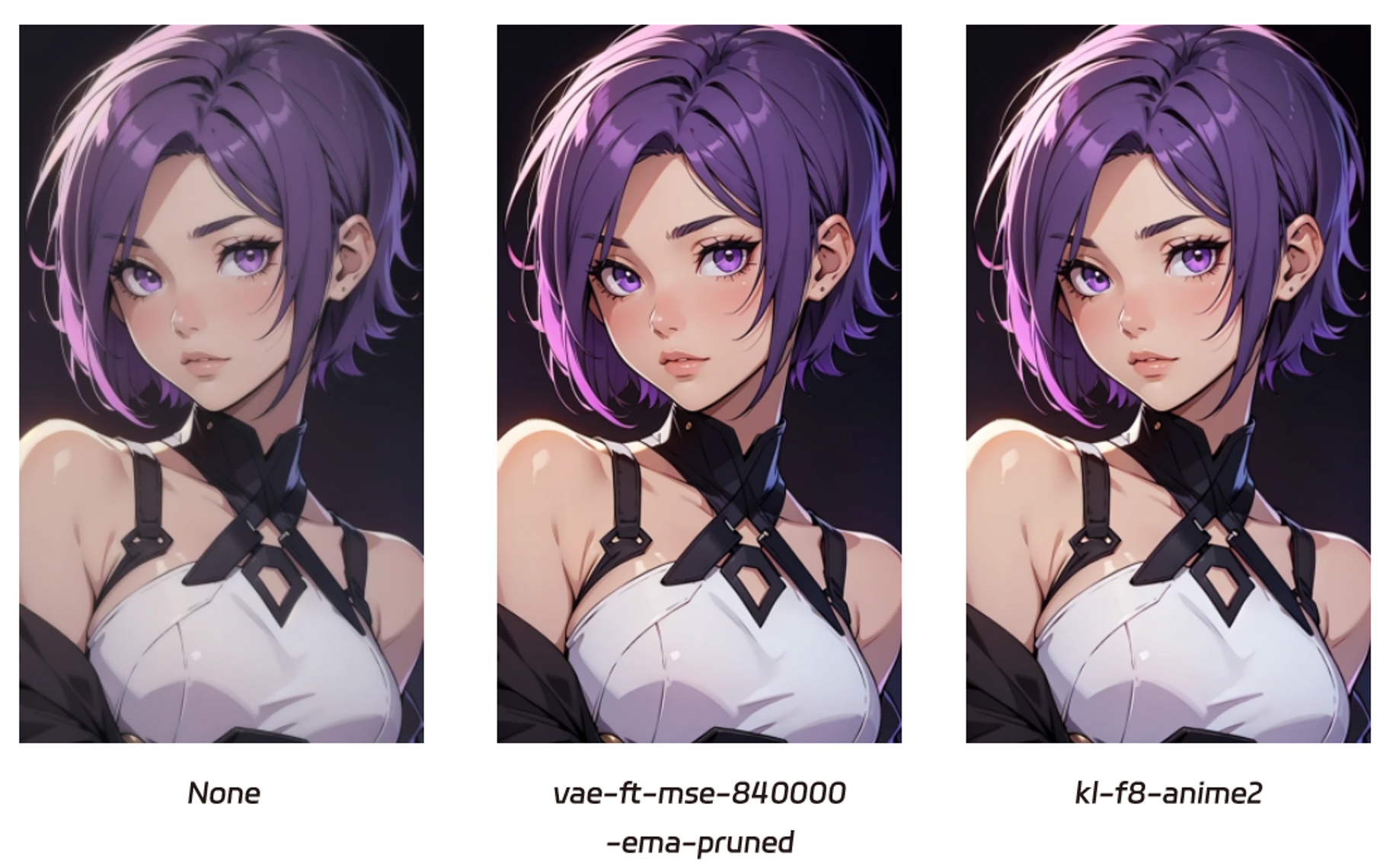
VAEs comúnmente usados:
Automático: Selecciona automáticamente la configuración VAE más adecuada para la tarea actual.
Ninguno: No usa VAE.
vae-ft-mse-840000-ema-pruned: Estilo color realista, 840000 indica las iteraciones de entrenamiento, mejora la calidad y reduce la complejidad aumentando la eficiencia.
vae-ft-ema-560000-ema-pruned: Estilo color realista, entrenado 560000 iteraciones, adecuado para generación rápida o con pocos recursos.
kl-f8-anime2: Optimizado para generar imágenes estilo anime.
*Algunos checkpoints incluyen VAE integrado, por lo que no es necesario seleccionar uno aparte.
Sampling (Muestreo)
Principio de muestreo
El proceso estándar de pintura con IA generalmente involucra una adición progresiva de ruido hacia adelante y luego un proceso inverso de eliminación de ruido (denoising), restauración y generación del objetivo. Durante el proceso hacia adelante, se añade ruido continuamente a los datos de entrada; el muestreador (sampler) se encarga de eliminar el ruido en el proceso inverso.

Proceso hacia adelante (de derecha a izquierda): Se añade ruido gradualmente a la imagen original, principalmente durante el entrenamiento para que la red U-Net aprenda a predecir el ruido.
Proceso hacia atrás (de izquierda a derecha): La red U-Net entrenada elimina progresivamente el ruido estimado, reproduciendo finalmente la imagen.
En estos dos procesos, la IA “desordena” una imagen específica y luego aprende a crear una nueva imagen a partir de partes de ella en sentido inverso. Es decir, una vez entrenado el proceso hacia adelante, el proceso hacia atrás genera una imagen completamente nueva a partir de una imagen ruidosa.
Antes de generar una imagen clara, el modelo necesita generar una imagen aleatoria en el espacio latente. El predictor de ruido comienza a trabajar restando el ruido estimado de la imagen. Con pasos repetidos, finalmente se obtiene una imagen clara. Todo el proceso de eliminación de ruido se denomina “sampling” (muestreo), y el método usado se llama sampler o método de muestreo.
El método de muestreo determina cómo se realiza la eliminación de ruido, y diferentes métodos producen diferentes resultados en las imágenes.
*El valor numérico del seed determina el ruido inicial de la primera imagen generada.

Métodos de muestreo
Solucionadores ODE clásicos
Euler: Método de Euler, el más simple.
Heun: Versión más precisa pero más lenta del método de Euler.
LMS: Método lineal multistep, misma velocidad que Euler pero más preciso.
Convergencia: A medida que aumenta el número de pasos de muestreo, los resultados tienden a converger hacia una imagen fija y estable.
Samplers ancestrales (nombres que incluyen una “a”)
Euler a
DPM2 a
DPM++ 2S a
DPM++ 2S a Karras
Estos samplers añaden ruido en cada paso, por lo que exhiben cierta aleatoriedad y no convergen.
No convergencia: Las imágenes son aleatorias y pueden agregar detalles, pero para obtener resultados estables y reproducibles, se recomienda evitar estos samplers.
* Algunos samplers, incluso sin la “a” en el nombre, también son aleatorios.
DDIM, PLMS (ya poco usados)
DDIM: Modelos implícitos de difusión con eliminación de ruido, primer sampler diseñado para modelos de difusión.
PLMS: Método pseudo lineal multistep, alternativa más rápida a DDIM.
Serie DPM y DPM++
Estos samplers tienen una alta utilización de etiquetas (tags), amplificando adecuadamente los pasos de muestreo para obtener mejores efectos, aunque la velocidad general es más lenta. DPM++ es una mejora de DPM, que ofrece resultados más precisos pero a un ritmo más lento.
Karras: Produce imágenes claras con menos pasos de muestreo, optimizando el algoritmo.
Restart: Utiliza menos pasos de muestreo para generar buenas imágenes en menos tiempo.
LCM: Genera imágenes rápidamente.

*Recomendaciones de uso:
Euler/Euler a: Velocidad rápida, alta calidad, adecuado para la mayoría de los escenarios, pasos recomendados 15-30.
DPM++2M Karras: Convergente, rápido, buena calidad (15-25 pasos).
DPM++SDE Karras: No convergente, lento, buena calidad, adecuado para imágenes realistas, recomendado 10-15 pasos.
DPM++2M SDE Karras: Algoritmo intermedio entre 2M y SDE, no convergente, velocidad un poco más rápida.
DPM++ 2M SDE Heun Exponential: No convergente, imagen suave y limpia, con menos detalles.
DPM++ 3M SDE Karras
DPM++ 3M SDE Exponential: Igual velocidad que 2M, requiere más pasos, cuando pasos > 30, reduce la intensidad del texto (CFG) para mejores resultados.
Restart: Velocidad muy rápida, solo para borradores o verificación rápida, resultados ideales con pocos pasos.
LCM: “Renderizado en tiempo real” en solo 4 pasos, calidad promedio, útil para bocetos o conceptos preliminares.
*Nota
I. Prioriza los algoritmos recomendados por el autor del modelo para mejor compatibilidad y eficacia.
II. Prioriza usar algoritmos con signo “+”, ya que suelen ser más estables que los sin él.
III. Si tienes problemas de ruido en las imágenes generadas, prueba otro sampler.
Pasos de muestreo
En general, cuanto mayor sea el número de pasos de muestreo, mejor será la calidad de la imagen. Sin embargo, alrededor de 25 pasos de muestreo suelen ser suficientes para obtener imágenes de alta calidad. Aumentar el número de pasos más allá de ese punto puede generar imágenes diferentes, pero no garantiza una mejor calidad. Además, más pasos implican mayor tiempo de espera. En la mayoría de los casos, no es necesario establecer un número excesivamente alto de pasos, ya que solo aumentaría el tiempo de generación sin aportar beneficios significativos.

A medida que aumenta el número de pasos de muestreo, la forma principal de la “chica” se mantiene relativamente consistente, mientras que ciertos detalles pequeños como la calidad del cabello, el color, el fondo, etc., mejoran progresivamente. Por lo tanto, el número de pasos de muestreo debe ajustarse según tus propias necesidades y prioridades en la generación de imágenes.
Escala CFG
Relación con los prompts: a mayor fuerza del texto, la imagen se acerca más al prompt. Normalmente se establece entre 7-10. Si es muy alto puede causar fallas. Si la imagen no sigue el prompt, aumenta la fuerza del texto.
Ejemplo de prompt: plano entero, pose de superhéroe, traje biomecánico, formas inflables, con implantes cibernéticos épicos, obra maestra, intrincado, vestuario biopunk futurista, muy detallado, artstation, arte conceptual, cyberpunk, render octane

Seed
Durante el proceso de generación de imágenes, existe una gran incertidumbre en el arte con IA, ya que cada dibujo implica un conjunto de mecanismos computacionales aleatorios, y cada uno de ellos corresponde a un valor de seed (semilla) fijo. Al fijar el valor de seed, podemos controlar la aleatoriedad de los resultados generados.
Por ejemplo, si estamos satisfechos con una imagen generada, podemos introducir su valor de seed aquí para reproducir el mismo contenido. Hacer clic en "Aleatorio" restablece la seed al valor predeterminado (-1), mientras que la opción "Personalizado" permite ingresar manualmente un valor de seed.
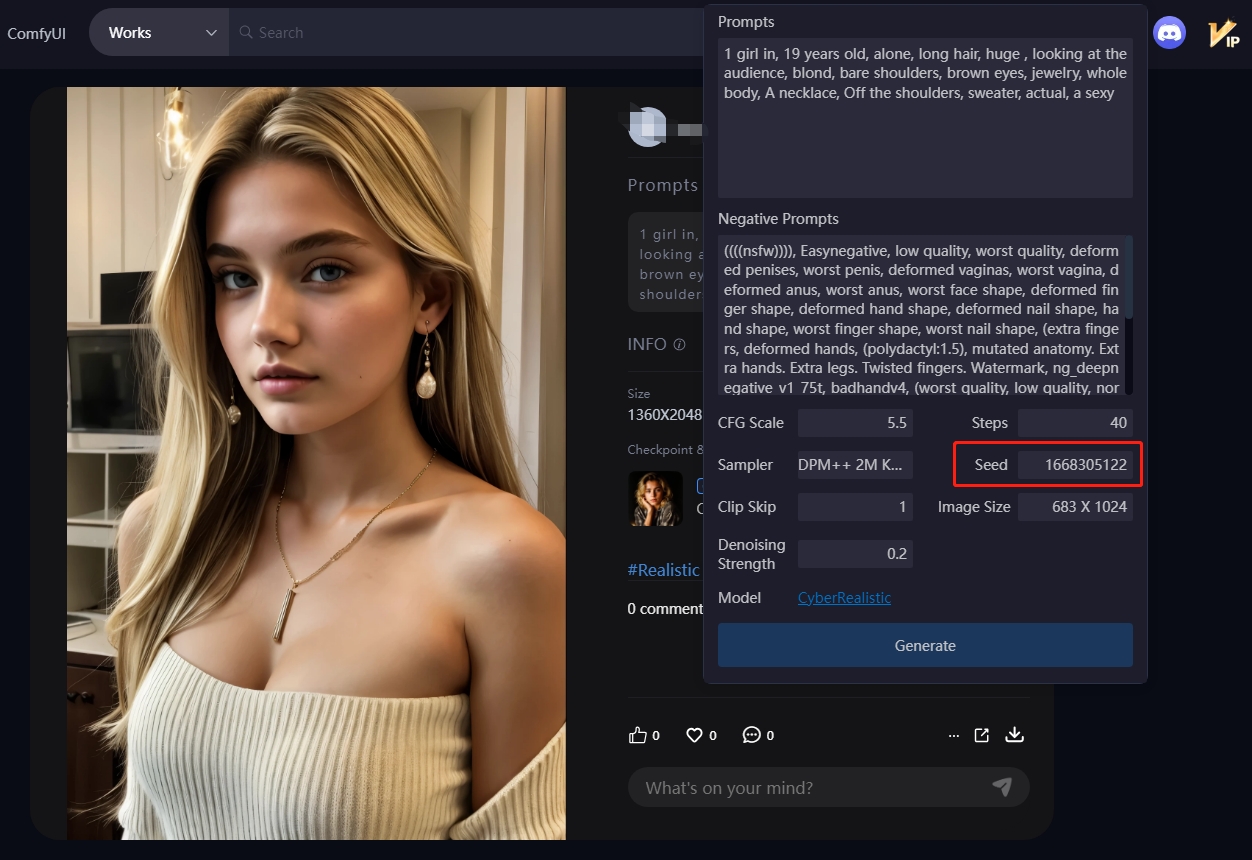
Usar los mismos parámetros, prompts y seed genera imágenes idénticas. Así puedes modificar parámetros manteniendo el seed para crear variaciones con características originales.

*Solo cambiar palabras emocionales para cambiar expresión facial, manteniendo cabello, ropa y fondo igual.
Clip Skip
Capa por capa, los prompts se transforman en números que el convertidor lee para entender progresivamente el prompt.
Si el prompt es: "Una chica joven, con un vestido negro, un sombrero negro, sosteniendo una varita, una bruja", cuando el valor de Clip Skip se establece en 2, la IA puede omitir conceptos como el vestido negro o la varita. A medida que aumenta el valor de Clip Skip, la IA omitirá más partes del prompt.
Por lo tanto, cuando Clip Skip se establece en 1, significa que se termina la lectura del prompt desde la última capa, y el resultado incluirá una descripción completa del prompt. Cuanto más temprano se detenga la lectura, menos descripción se obtendrá del prompt, lo que resultará en menor precisión en el resultado final. Por lo general, se establece en 2.
¿Para qué sirve Clip Skip?
Clip Skip ayuda a evitar sobreajustes cortando a tiempo la lectura del prompt. Si la imagen está sobreajustada, aumenta Clip Skip.
Configurando Clip Skip puedes ajustar detalles y estilo del arte con IA, haciendo el resultado final más flexible y controlable, para cumplir con distintas necesidades.
Prompts: mejor calidad, obra maestra, ilustración, brillo detallado y hermoso, sombreado textil, resolución absurda, alta resolución, iluminación dinámica, detalles intrincados, ojos hermosos, [contraluz], iluminación facial, (punto de vista:1.3), (1 chica, sola:1.5), flequillo asimétrico, cabello negro, (sonrisa), (pantalones vaqueros y camisa)
