3-2 Entrenamiento de LoRA (Avanzado)
¡Domina el arte con IA con el entrenamiento avanzado de LoRA! Esta guía cubre desde los principios y procesos básicos hasta la optimización de parámetros para obtener resultados únicos y controlables.
1. Principio de LoRA
¿Para qué sirve LoRA?
LoRA permite afinar toda la imagen sin modificar los pesos del modelo Checkpoint. En este caso, solo necesitas ajustar el archivo LoRA para generar imágenes específicas sin alterar el modelo completo. Para imágenes que la IA no ha visto antes, LoRA permite una personalización fina que le otorga al arte con IA un mayor grado de “controlabilidad”.
Entrenamiento de imágenesActualmente, los modelos entrenados son refinamientos sobre modelos oficiales como SD1.5 o SDXL, aunque también pueden basarse en modelos creados por otros usuarios.
Entrenamiento de videoEntrenamiento de LoRA:
Primero, la IA genera imágenes basándose en las indicaciones y, a continuación, las compara con el conjunto de datos del conjunto de entrenamiento. Al guiar a la IA para que ajuste continuamente los vectores de incrustación basándose en las diferencias generadas, los resultados generados se aproximan gradualmente al conjunto de datos. Finalmente, el modelo ajustado puede producir resultados completamente equivalentes al conjunto de datos, formando una asociación entre las imágenes generadas por la IA y el conjunto de datos, haciéndolas cada vez más similares.
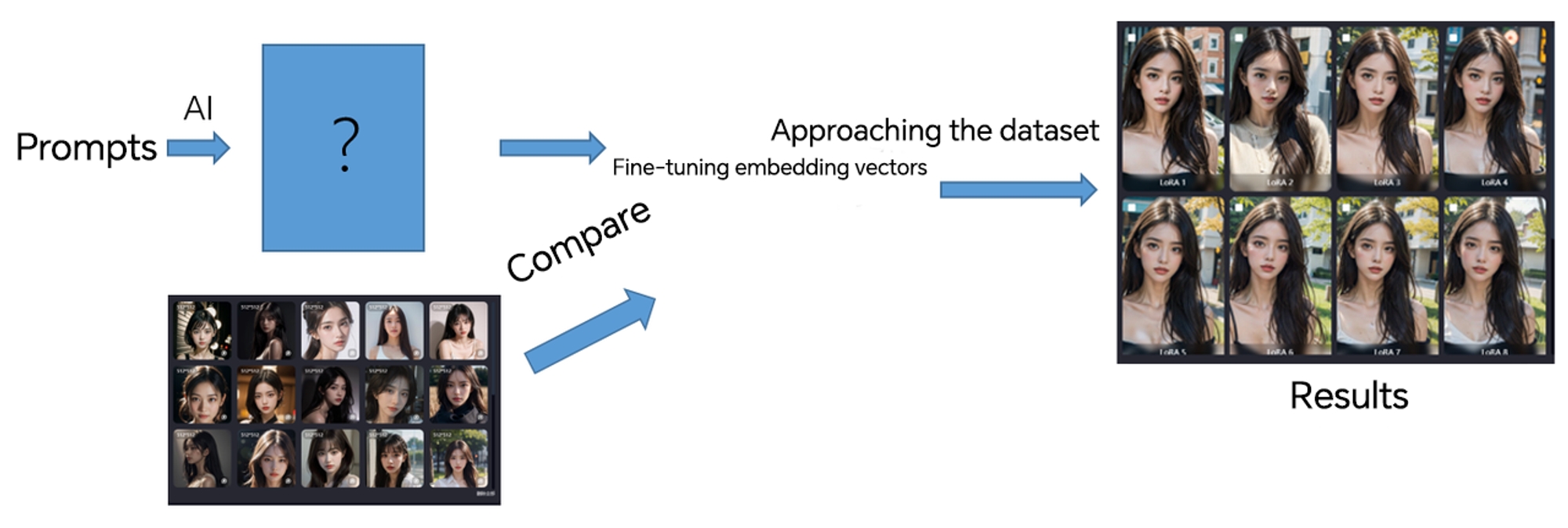
*Comparado con un Checkpoint, LoRA ocupa mucho menos espacio, ahorra tiempo y recursos, y permite ajustes adicionales sobre el modelo base.
2. Proceso de entrenamiento de LoRA
Cinco pasos: Preparar el conjunto de datos - Preprocesar las imágenes - Establecer parámetros - Supervisar el proceso de entrenamiento de Lora - Finalizar el entrenamiento
*Tomando como ejemplo el entrenamiento de una Lora facial con SeaArt.
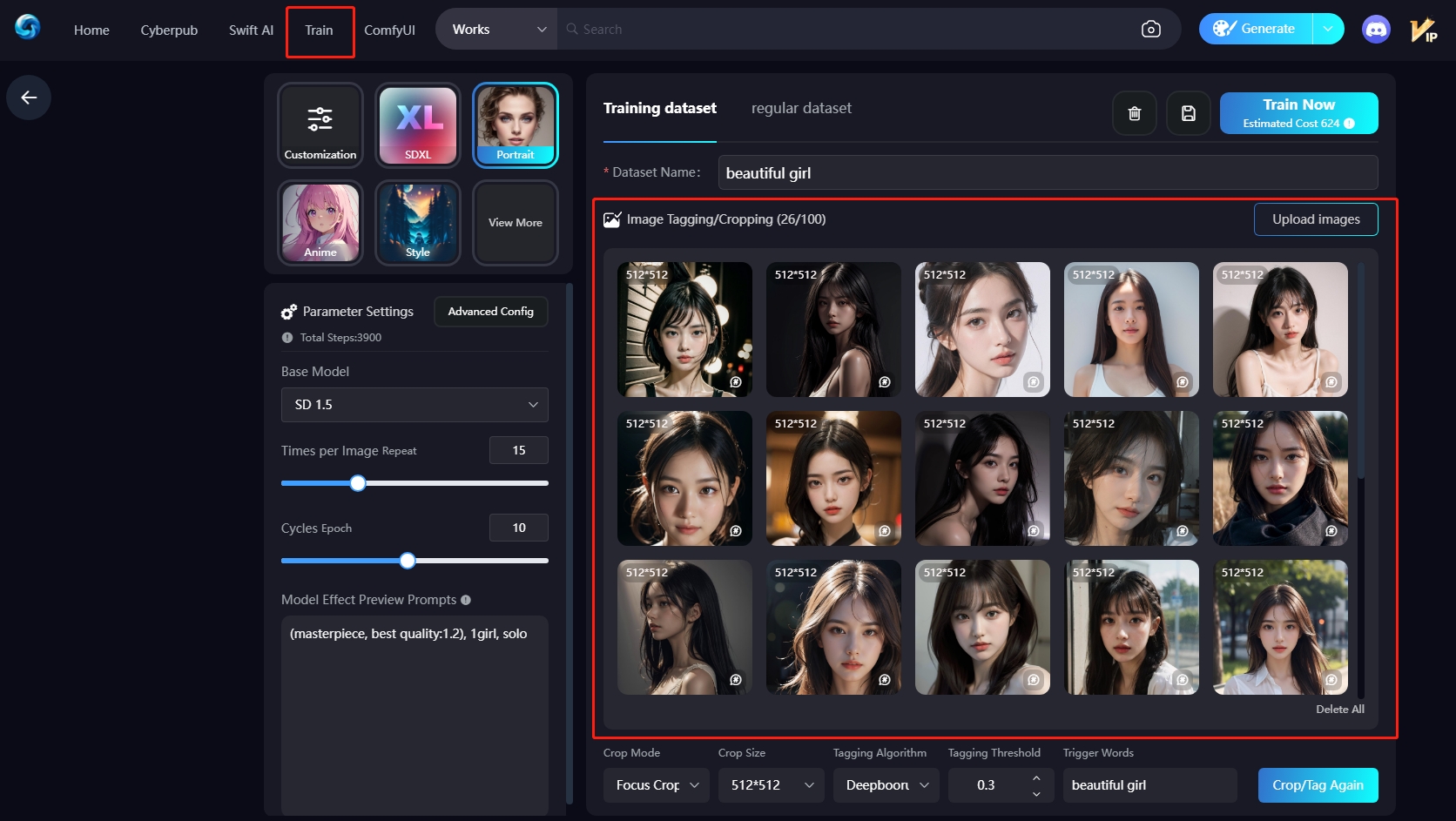
Prepara el conjunto de datos
*Para más información sobre cómo crearlo, consulta la guía correspondiente siguiente.
Cómo crear un conjunto de datos para el entrenamientoAl cargar el conjunto de datos, es esencial mantener el principio de "muestras diversificadas" Esto significa que el conjunto de datos debe incluir imágenes desde diferentes ángulos, poses, condiciones de iluminación, etc., y asegurarte de que las imágenes son de alta resolución. Este paso tiene como principal objetivo ayudar a la IA a comprender las imágenes.
Preprocesamiento de imágenes
I. Recorte de imágenes II. Etiquetado III. Palabras desencadenantes
I. Recorte de imágenes
Para que la IA pueda reconocer mejor los objetos en las imágenes, lo ideal es mantener dimensiones consistentes. Puedes elegir entre 512×512 (1:1), 512×768 (2:3) o 768×512 (3:2), según el resultado deseado.
Modo de recorte: Recorte centrado / Recorte enfocado / Sin recorte
Recorte centrado: recorta la región central de la imagen.
Recorte enfocado: identifica automáticamente el sujeto principal de la imagen.


*En comparación con el recorte centrado, el recorte enfocado tiene más probabilidades de preservar el sujeto principal del conjunto de datos, por lo que se recomienda utilizar el recorte enfocado.
II. Etiquetado
Consiste en proporcionar descripciones textuales para las imágenes del conjunto de datos, lo que permite a la IA aprender a partir del contenido escrito.
Algoritmo de etiquetado: BLIP / Deepbooru
BLIP: Etiquetador en lenguaje natural, por ejemplo: “una chica con cabello negro”.
Deepbooru: Etiquetas por frases, por ejemplo: “una chica, cabello negro”.
Umbral de etiquetado: Cuanto menor sea el valor, más detallada será la descripción. Se recomienda un valor de 0.6.
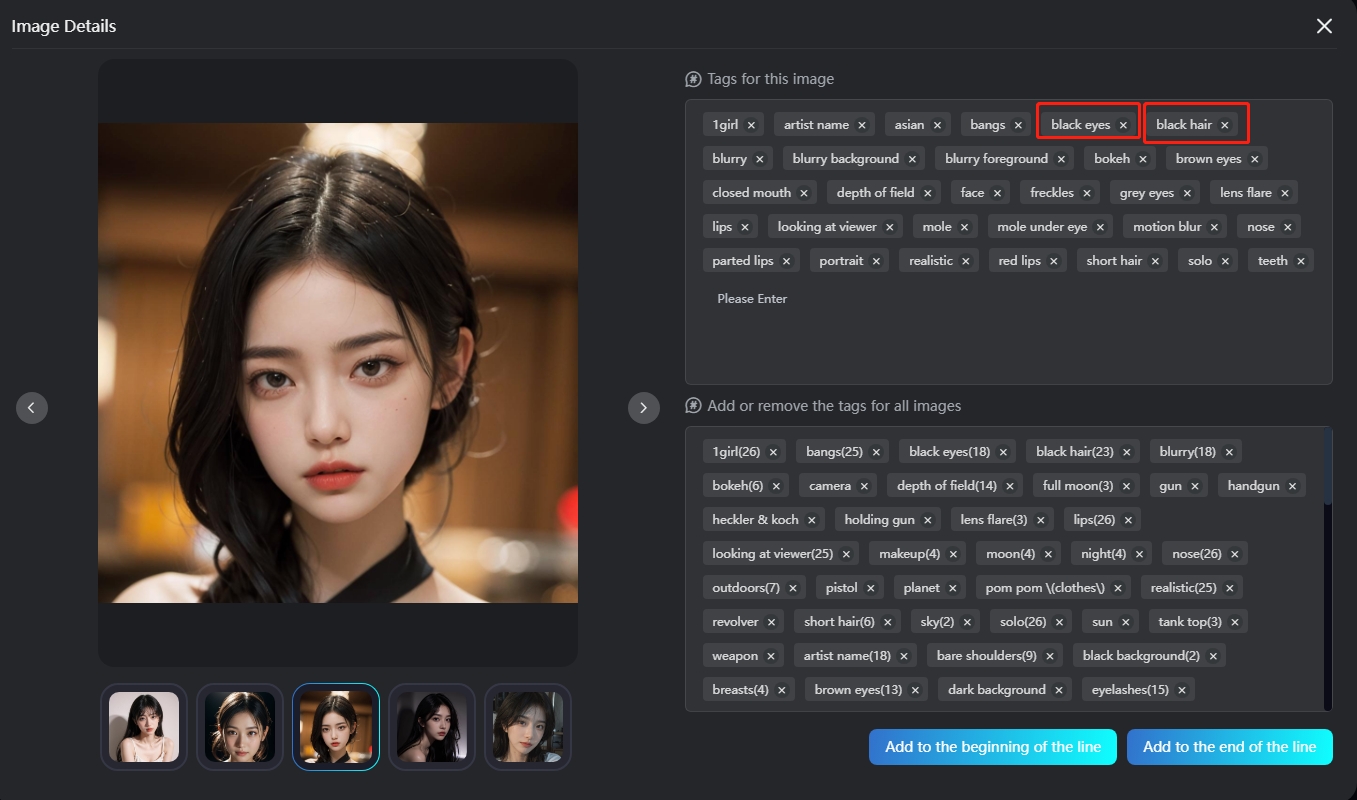
Proceso de etiquetado: Elimina las características fijas (como rasgos físicos...) para permitir que la IA las aprenda de forma autónoma. Del mismo modo, puedes añadir ciertas características que desees ajustar en el futuro (ropa, accesorios, acciones, fondo...).
*Por ejemplo, si deseas que todas las imágenes generadas tengan cabello negro y ojos negros, puedes eliminar esas dos etiquetas.
III. Palabras desencadenantes
Palabras que activan la LoRA, consolidando las características del personaje en una sola palabra.

Parámetros de configuración
Modelo Base: Se recomienda elegir un modelo base estable y de alta calidad que se asemeje al estilo de la LoRA para facilitar que la IA capture las características y diferencias.
Modelos base recomendados:
Realista: SD1.5, ChilloutMix, MajicMIX Realistic, Realistic Vision
Anime: AnyLoRA, Anything | 万象熔炉, ReV Animated
Configuración avanzada de entrenamiento
Parámetros de entrenamiento:
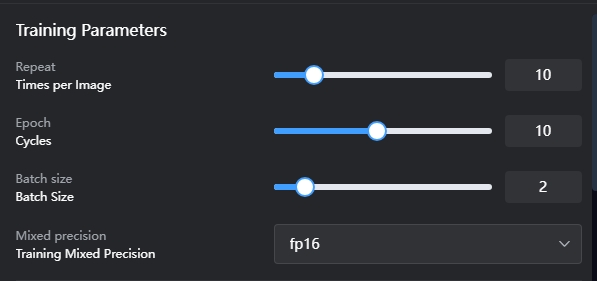
Repeat (Repeticiones por imagen): Número de veces que se aprende una imagen individual. Más repeticiones mejoran el aprendizaje, pero excesivas pueden causar rigidez. Sugerencia: Anime = 8; Realista = 15.
Epoch (Ciclos): Un ciclo equivale al número de imágenes del conjunto de datos multiplicado por el valor de Repeat (repeticiones por imagen). Representa la cantidad total de pasos que el modelo ha entrenado sobre el conjunto de datos. Por ejemplo, si tienes 20 imágenes y Repeat está configurado en 10, entonces cada ciclo corresponde a 20 × 10 = 200 pasos. Si configuras Epoch en 10, el entrenamiento total de la LoRA será de 200 × 10 = 2000 pasos. Sugerencias: Anime: 20 Epochs; Realista: 10 Epochs.
Batch size (Tamaño de lote): Se refiere a la cantidad de imágenes que la IA procesa y aprende simultáneamente. Por ejemplo, si se configura en 2, la IA aprende 2 imágenes al mismo tiempo, lo que reduce la duración total del entrenamiento. Sin embargo, procesar varias imágenes a la vez puede disminuir ligeramente la precisión del aprendizaje para cada imagen.
Mixed precision (Precisión mixta): Se recomienda utilizar fp16.
Configuración de muestra:
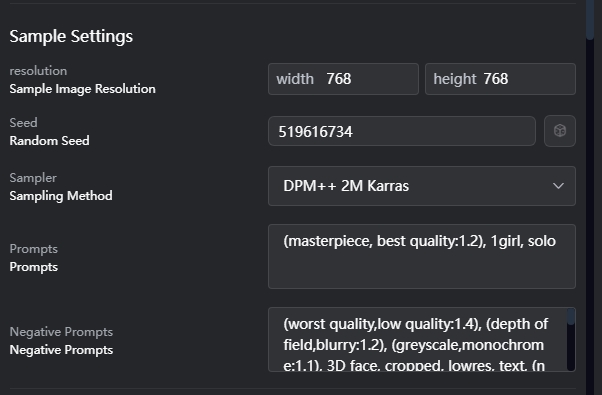
Resolución: Determina el tamaño de la imagen de previsualización del efecto final del modelo.
SD1.5: 512x512
SD1.5: 512x512
Seed: Controla las imágenes generadas aleatoriamente. Si se utiliza la misma semilla r con indicaciones, es probable que se generen imágenes iguales/similares.
Muestra \ Prompts \ Prompts negativos: Principalmente muestran el efecto de la imagen de vista previa del modelo final.
Guardar ajustes:
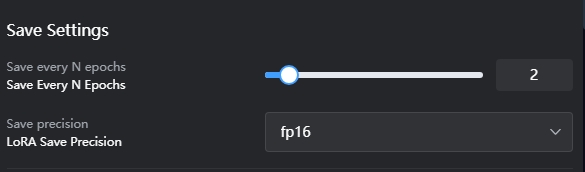
Determina el número final de Loras. Si se establece en 2, y la Época es 10, al final se guardarán 5 Loras.
Precisión de guardado: Se recomienda utilizar fp16.
Tasa de aprendizaje y optimizador:
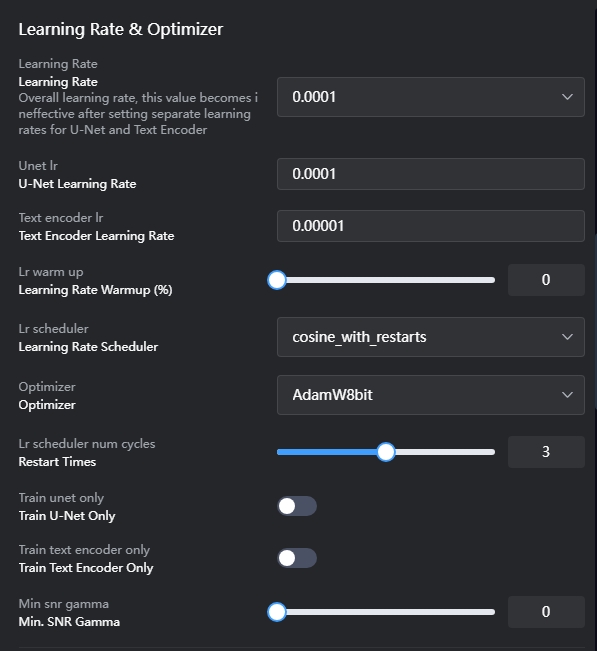
Tasa de aprendizaje (Learning Rate): Indica la intensidad con la que la IA aprende del conjunto de datos. Cuanto mayor sea la tasa de aprendizaje, más puede aprender la IA, pero también puede provocar imágenes de salida disímiles. Cuando el dataset aumenta, es recomendable intentar reducir la tasa de aprendizaje. Se recomienda comenzar con el valor predeterminado y luego ajustarlo según los resultados del entrenamiento. Se sugiere aumentar gradualmente desde una tasa de aprendizaje baja, recomendada en 0.0001.
unet lr: Cuando se establece el unet lr, la tasa de aprendizaje (Learning Rate) general no tendrá efecto. Se recomienda un valor de 0.0001.
text encoder lr: Determina la sensibilidad a las etiquetas (tags). Por lo general, el text encoder lr se configura en 1/2 o 1/10 del valor de unet lr.
Lr scheduler: Principalmente regula la disminución (decay) de la tasa de aprendizaje. Los diferentes schedulers tienen un impacto mínimo en los resultados finales. Generalmente se usa el scheduler por defecto llamado "cosine", pero también está disponible una versión mejorada llamada "Cosine with Restart". Esta versión realiza múltiples reinicios y decaimientos para aprender completamente el dataset, evitando interferencias de "soluciones óptimas locales" durante el entrenamiento. Si se usa "Cosine with Restart", configure el número de reinicios (Restart Times) entre 3 y 5.
Optimizer (Optimizador): Determina cómo la IA comprende el proceso de aprendizaje durante el entrenamiento, impactando directamente en los resultados del aprendizaje. Se recomienda usar AdamW8bit.
Lion: Un optimizador recientemente introducido, que generalmente utiliza una tasa de aprendizaje aproximadamente 10 veces menor que la de AdamW.
Prodigy: Si todas las tasas de aprendizaje se configuran en 1, Prodigy ajustará automáticamente la tasa de aprendizaje para obtener los mejores resultados, siendo adecuado para principiantes.
Red (Network):
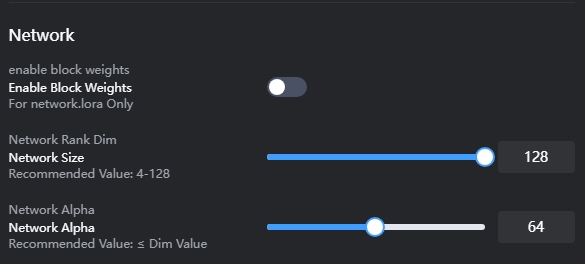
Se utiliza para construir una base de modelo LoRA adecuada para los datos de entrada de la IA.
Network Rank Dim: Afecta directamente al tamaño de la LoRA. Cuanto mayor sea el Rank, más datos deben ajustarse finamente durante el entrenamiento. 128 = más de 140 MB; 64 = más de 70 MB; 32 = más de 40 MB.
Recomendado:
Realista: 64 / 128
Anime: 8 / 16 / 32
Configurar un valor demasiado alto hará que la IA aprenda en exceso, capturando muchos detalles irrelevantes, lo cual es similar al “sobreajuste” (overfitting).
Network Alpha: Se puede entender como el grado de influencia de la LoRA sobre los pesos del modelo original. Cuanto más se acerque al valor de Rank, menor será la influencia sobre los pesos originales; cuanto más se acerque a 0, mayor será dicha influencia. En general, Alpha no supera el valor de Rank. Actualmente, Alpha suele configurarse en la mitad de Rank. Si se establece en 1, se maximiza la influencia sobre los pesos.
Configuración de etiquetado:
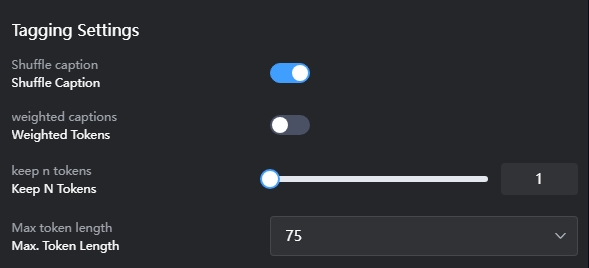
En general, cuanto más cerca esté una etiqueta del principio, mayor será su peso. Por lo tanto, normalmente se recomienda activar Shuffle Caption.
3. Problemas en el entrenamiento de LoRA
3.1 Sobreajuste / Subajuste
Sobreajuste (Overfitting): Ocurre cuando el conjunto de datos es limitado o cuando la IA se ajusta demasiado al dataset, lo que hace que la LoRA genere imágenes que se parecen mucho al conjunto de entrenamiento, resultando en una baja capacidad de generalización del modelo.

La imagen en la parte superior derecha se parece mucho al conjunto de datos de la izquierda, tanto en apariencia como en postura.
Causas del sobreajuste:
El conjunto de datos es insuficiente.
Configuración incorrecta de parámetros (etiquetas, tasa de aprendizaje, pasos, optimizador, etc.).
Cómo prevenir el sobreajuste:
Disminuir adecuadamente la tasa de aprendizaje.
Acortar los Epoch.
Reducir el Rank y aumentar el Alpha.
Disminuir el valor de Repeat.
Utilizar entrenamiento con regularización.
Aumentar el tamaño del conjunto de datos.
Subajuste (Underfitting): El modelo no logra aprender adecuadamente las características del conjunto de datos durante el entrenamiento, lo que resulta en imágenes generadas que no coinciden bien con el dataset.

Puede observar que las imágenes generadas por Lora no conservan adecuadamente las características del conjunto de datos y no son similares.
Causas del subajuste:
Baja complejidad del modelo.
Cantidad insuficiente de características en el dataset.
Cómo prevenir el subajuste:
Incrementar adecuadamente la tasa de aprendizaje.
Aumentar los Epoch.
Elevar el Rank y reducir el Alpha.
Incrementar el valor de Repeat.
Reducir las restricciones de regularización.
Añadir más características al dataset (de alta calidad).
3.2 Dataset Regular (Conjunto de datos regular)
Una forma de evitar el sobreajuste de las imágenes es agregar imágenes adicionales para mejorar la capacidad de generalización del modelo. El conjunto de datos regular no debe ser demasiado extenso, ya que de lo contrario la IA aprenderá en exceso de este conjunto, lo que podría generar inconsistencias con el objetivo original. Se recomienda contar con entre 10 y 20 imágenes.
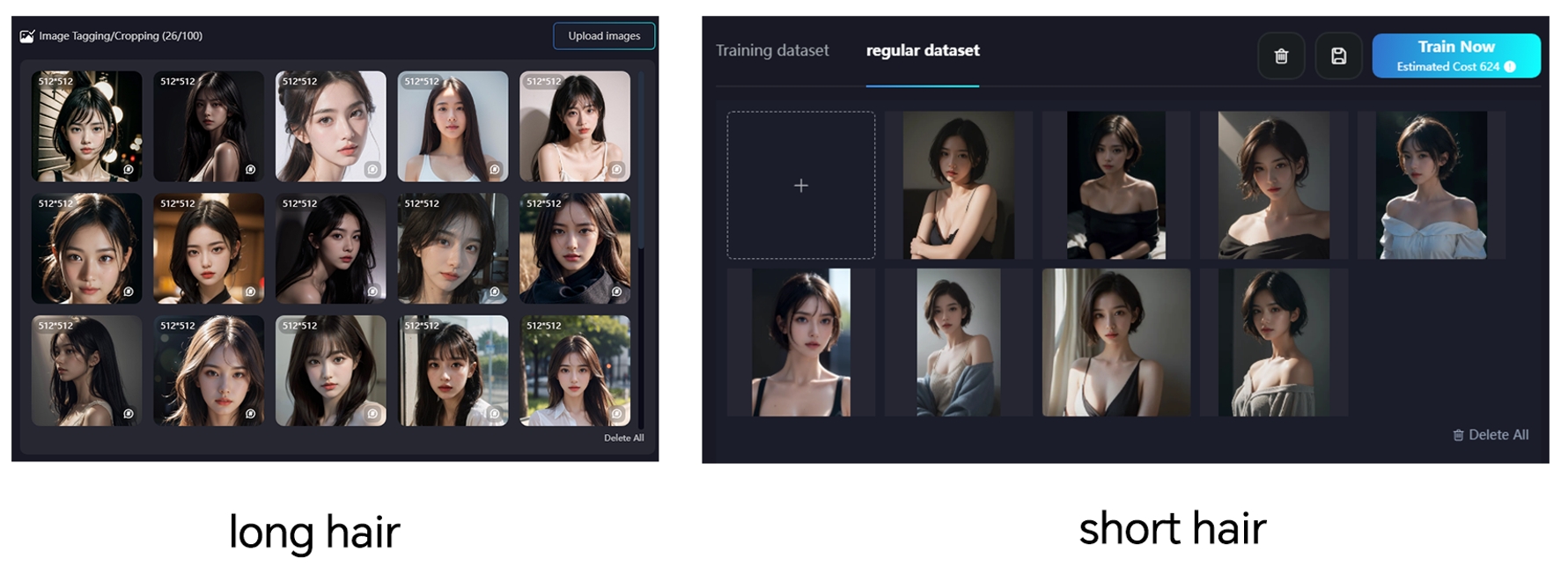
Por ejemplo, en un conjunto de datos de retratos donde la mayoría de las imágenes muestran cabello largo, puedes agregar imágenes con cabello corto al conjunto de datos regular. De manera similar, si el dataset está compuesto únicamente por imágenes con el mismo estilo artístico, puedes añadir imágenes con estilos diferentes al conjunto regular para diversificar el modelo. El conjunto de datos regular no necesita estar etiquetado.
*En términos sencillos, entrenar LoRA de esta manera es algo así como combinar el dataset principal con un conjunto de datos regular.
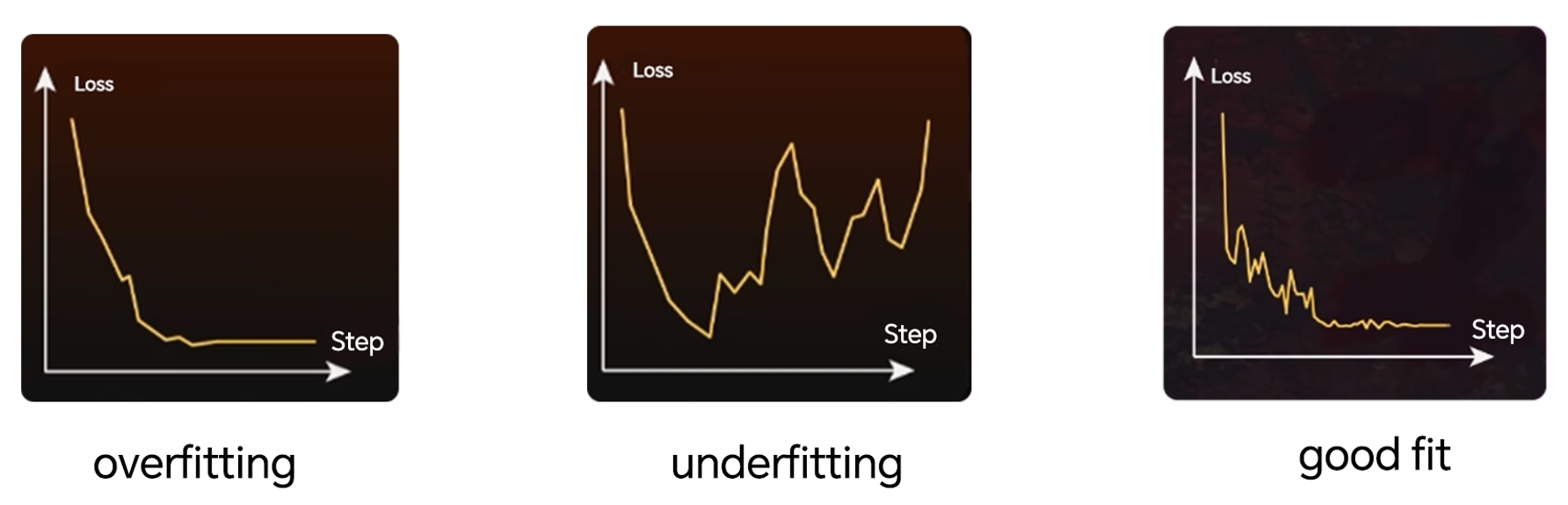
3.3 Pérdida (Loss)
La desviación entre lo que la IA aprende y la realidad, guiada por la pérdida, puede optimizar la dirección del aprendizaje de la IA. Por lo tanto, cuando la pérdida es baja, la desviación entre lo aprendido y la realidad es relativamente pequeña, y en ese punto la IA aprende con mayor precisión. Mientras la pérdida disminuya gradualmente, por lo general no hay problemas importantes.
El valor de pérdida para imágenes realistas suele estar entre 0.1 y 0.12, mientras que para anime puede reducirse adecuadamente.
Usa el valor de la pérdida para evaluar posibles problemas en el entrenamiento del modelo.
3.4 Resumen
Actualmente, los modelos de “fine-tuning” se pueden dividir aproximadamente en tres tipos: los Checkpoints generados por Dreambooth, las LoRA y los Embeddings generados por Textual Inversion. Considerando factores como el tamaño del modelo, la duración del entrenamiento y los requisitos del conjunto de datos, LoRA ofrece la mejor “relación costo-beneficio”. Ya sea para ajustar el estilo artístico, personajes o distintas poses, LoRA puede desempeñarse de manera efectiva.

4. Configuración SDXL LoRA
4.1 Parámetros recomendados para el entrenamiento
Epochs y Repeats
Epochs: Número de ciclos de entrenamiento sobre las imágenes del conjunto de datos. Recomendamos 10 para principiantes. El valor puede aumentarse si el entrenamiento parece insuficiente debido a un conjunto de datos pequeño, o reducirse si el conjunto de datos es muy grande.
Repeats: Número de veces que se aprende una imagen. Valores más altos conducen a mejores resultados y composiciones de imagen más complejas. Sin embargo, configurarlo demasiado alto puede aumentar el riesgo de sobreajuste. Por ello, sugerimos usar 10 para lograr buenos resultados y minimizar la posibilidad de sobreajuste.
*Nota: Puedes aumentar los epochs y repeats si los resultados del entrenamiento no se parecen al objetivo.
4.2 Tasa de aprendizaje y optimizador
learning_rate (Tasa de aprendizaje general)
Grado de cambio en cada repetición. Valores más altos significan un aprendizaje más rápido, pero pueden causar fallos en el modelo o que no converja. Valores más bajos significan un aprendizaje más lento, pero pueden alcanzar un estado óptimo. Este valor deja de tener efecto cuando se establecen tasas de aprendizaje separadas para U-Net y Text Encoder.
unet_lr (Tasa de aprendizaje de U-Net)
U-Net guía las imágenes con ruido generadas por semillas aleatorias para determinar la dirección de eliminación de ruido, encontrar las áreas que requieren cambios y proporcionar los datos necesarios. Valores más altos significan un ajuste más rápido pero con riesgo de perder detalles, mientras que valores más bajos causan subajuste y falta de semejanza entre las imágenes generadas y el material original. El valor se establece según el tipo de modelo y conjunto de datos. Sugerimos 0.0002 para el entrenamiento de personajes.
text_encoder_lr (Tasa de aprendizaje del codificador de texto) Convierte las etiquetas en forma de embeddings para que U-Net pueda entenderlas. Dado que el codificador de texto de SDXL ya está bien entrenado, generalmente no es necesario un entrenamiento adicional, y los valores predeterminados son adecuados a menos que existan necesidades especiales.
Optimizador Es un algoritmo de aprendizaje profundo que ajusta los parámetros del modelo para minimizar la función de pérdida. Durante el entrenamiento de redes neuronales, el optimizador actualiza los pesos del modelo basándose en la información del gradiente de la función de pérdida para que el modelo se ajuste mejor a los datos de entrenamiento. El optimizador predeterminado, AdamW, puede usarse para el entrenamiento de SDXL, y otros optimizadores, como Prodigy, que es fácil de usar y cuenta con tasas de aprendizaje adaptativas, también pueden elegirse según los requisitos específicos.
lr_scheduler (Configuración del programador de tasa de aprendizaje):
Se refiere a una estrategia o algoritmo para ajustar dinámicamente la tasa de aprendizaje durante el entrenamiento. Bajo circunstancias normales, elegir la opción Constant es suficiente.
4.3 Configuración de red
network_dim (Dimensión de la red):
Está estrechamente relacionada con el tamaño de la LoRA entrenada.
Para SDXL, una LoRA de 32 dimensiones ocupa 200 MB, una de 16 dimensiones ocupa 100 MB, y una de 8 dimensiones ocupa 50 MB. Para personajes, seleccionar 8 dimensiones es suficiente.
network_alpha:
Generalmente se establece como la mitad o un cuarto del valor de la dimensión (dim). Por ejemplo, si dim está configurado en 8, entonces alpha puede establecerse en 4.
4.4 Otros ajustes:
Resolución: La resolución de entrenamiento puede ser rectangular, pero debe ser múltiplo de 64. Para SDXL, recomendamos 1024×1024 o 1024×768.
enable_bucket (Bucket): Si las resoluciones de las imágenes no están unificadas, activa este parámetro. Clasificará automáticamente la resolución del conjunto de entrenamiento y creará un bucket para almacenar las imágenes de cada resolución o resoluciones similares antes de que comience el entrenamiento. Esto ahorra tiempo en la unificación de resolución durante las etapas iniciales. Si las resoluciones ya están unificadas, no es necesario activarlo.
noise_offset y multires_noise_iterations: Ambos parámetros de compensación de ruido ayudan a corregir situaciones en las que la imagen generada es demasiado brillante o demasiado oscura. Si el conjunto de entrenamiento no contiene imágenes excesivamente brillantes u oscuras, se pueden desactivar. Si se activan, se recomienda usar multires_noise_iterations con un valor entre 6 y 10.
multires_noise_discount:
Debes activarlo junto con multires_noise_iterations mencionado anteriormente, y se recomienda que uses un valor entre 0.3 y 0.8.
clip_skip:
Te permite especificar qué capa de salida del codificador de texto deseas usar, contando desde la última. Por lo general, el valor predeterminado es suficiente para ti.